NLP

X.com
24561
Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest
Addison J. Wu, Ryan Liu, Shuyue Stella Li, Yulia Tsvetkov, Thomas L. Griffiths
The most upvoted and starred AI research crossing the community today.
Last Brew Time: May 8, 2026, 9:34 AM PT
Addison J. Wu, Ryan Liu, Shuyue Stella Li, Yulia Tsvetkov, Thomas L. Griffiths

Mrinank Sharma, Miles McCain, Raymond Douglas, David Duvenaud

Natalie Shapira, Chris Wendler, Avery Yen, Gabriele Sarti, Koyena Pal, Olivia Floody, Adam Belfki, Alex Loftus, Aditya Ratan Jannali, Nikhil Prakash, Jasmine Cui, Giordano Rogers, Jannik Brinkmann, Can Rager, Amir Zur, Michael Ripa, Aruna Sankaranarayanan, David Atkinson, Rohit Gandikota, Jaden Fiotto-Kaufman, EunJeong Hwang, Hadas Orgad, P Sam Sahil, Negev Taglicht, Tomer Shabtay, Atai Ambus, Nitay Alon, Shiri Oron, Ayelet Gordon-Tapiero, Yotam Kaplan, Vered Shwartz, Tamar Rott Shaham, Christoph Riedl, Reuth Mirsky, Maarten Sap, David Manheim, Tomer Ullman, David Bau

Haoquan Fang, Jiafei Duan, Donovan Clay

Thinking Machines, Kevin Lu
Thinking Machines

Chloe Li, Sara Price, Samuel Marks
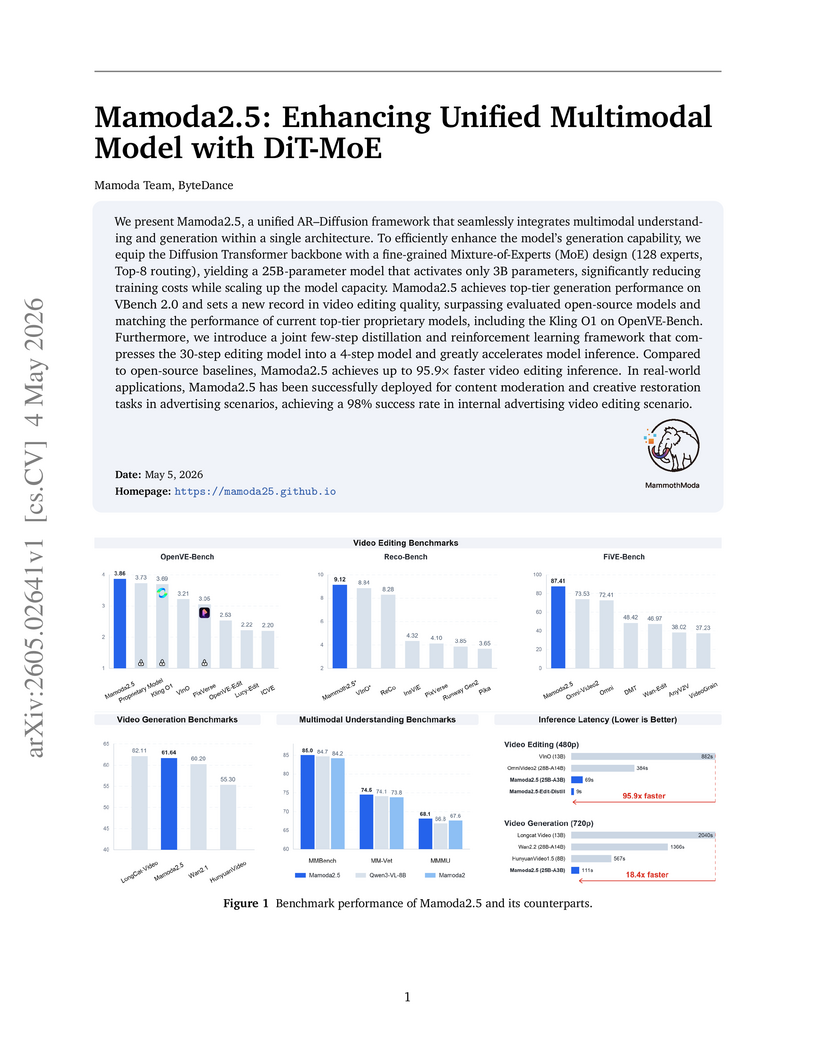
ByteDance, Yangming Shi, Shixiang Zhu, Tao Shen
ByteDance

Dongyoung Kim, Huiwon Jang, Myungkyu Koo

John Yang, Kilian Lieret, Jeffrey Ma

Zhuofeng Li, Haoxiang Zhang, Cong Wei, Pan Lu, Ping Nie

You Qin, Kai Liu, Shengqiong Wu, Kai Wang, Shijian Deng

Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr

Justin Lovelace, Christian Belardi, Srivatsa Kundurthy, Shriya Sudhakar, Kilian Q. Weinberger

Yu-Cheng Lin, Yu-Chao Hsu, I-Shan Tsai, Chun-Hua Lin, Kuo-Chung Peng

Pranav Mantini, Shishir K. Shah
System online.