Efficiency
AlphaXiv
171
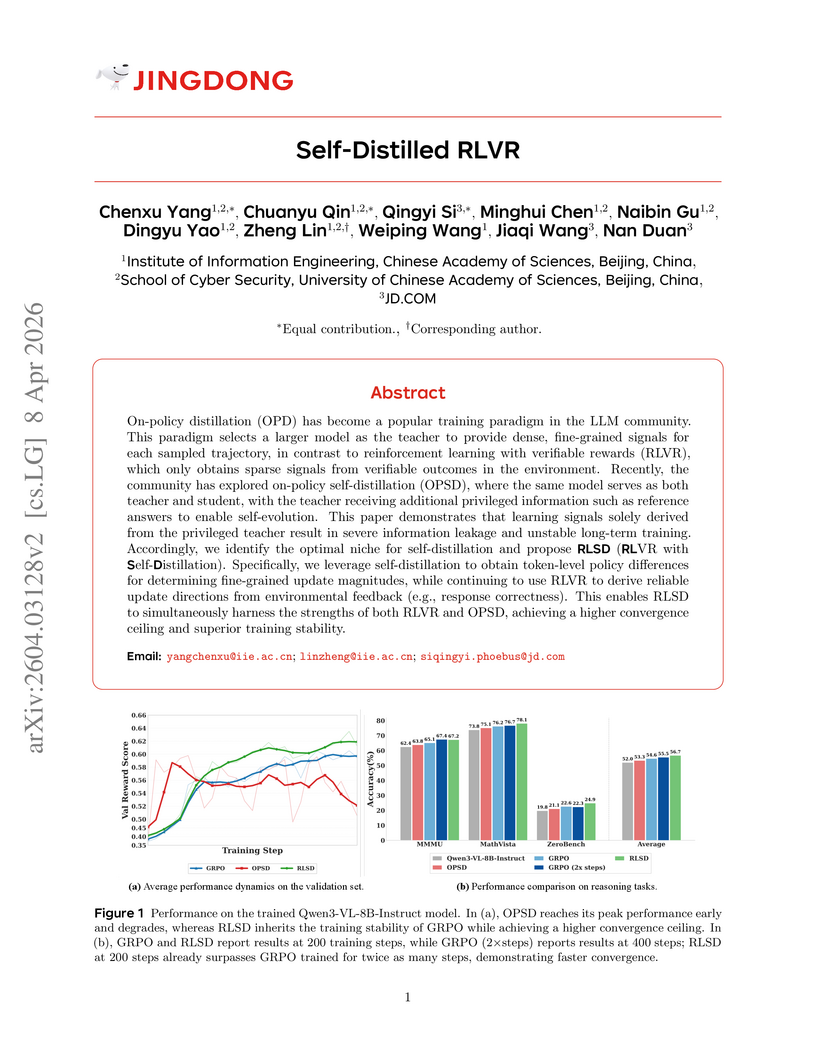
Self-Distilled RLVR
Chenxu Yang, Chuanyu Qin, Qingyi Si
The most upvoted and starred AI research crossing the community today.
Last Brew Time: Apr 10, 2026, 11:48 AM PT
Chenxu Yang, Chuanyu Qin, Qingyi Si

Guhao Feng, Shengjie Luo, Kai Hua

Weian Mao, Xi Lin, Wei Huang

Chenxi Wang, Zhuoyun Yu, Xin Xie

Gabriel Sarch, Linrong Cai, Qunzhong Wang

Yiwen Song, Tomas Pfister

Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao

Rishab Balasubramanian, Pin-Jie Lin, Rituraj Sharma, Anjie Fang, Fardin Abdi

Junjie Fei, Jun Chen, Zechun Liu, Yunyang Xiong, Chong Zhou

Sai Srinivas Kancheti, Aditya Kanade, Rohit Sinha, Vineeth N Balasubramanian, Tanuja Ganu

Pardis Taghavi, Tian Liu, Renjie Li, Reza Langari, Zhengzhong Tu

Samer Abualhanud, Christian Grannemann, Max Mehltretter
System online.