NLP

X.com
33195
Ads in AI Chatbots? An Analysis of How Large Language Models Navigate Conflicts of Interest
Addison J. Wu, Ryan Liu, Shuyue Stella Li, Yulia Tsvetkov, Thomas L. Griffiths
Princeton University, University of Washington
The most upvoted and starred AI research crossing the community today.
Last Brew Time: May 9, 2026, 9:53 AM PT
Addison J. Wu, Ryan Liu, Shuyue Stella Li, Yulia Tsvetkov, Thomas L. Griffiths
Princeton University, University of Washington

Mrinank Sharma, Miles McCain, Raymond Douglas, David Duvenaud
Anthropic, ACS Research Group, University of Toronto
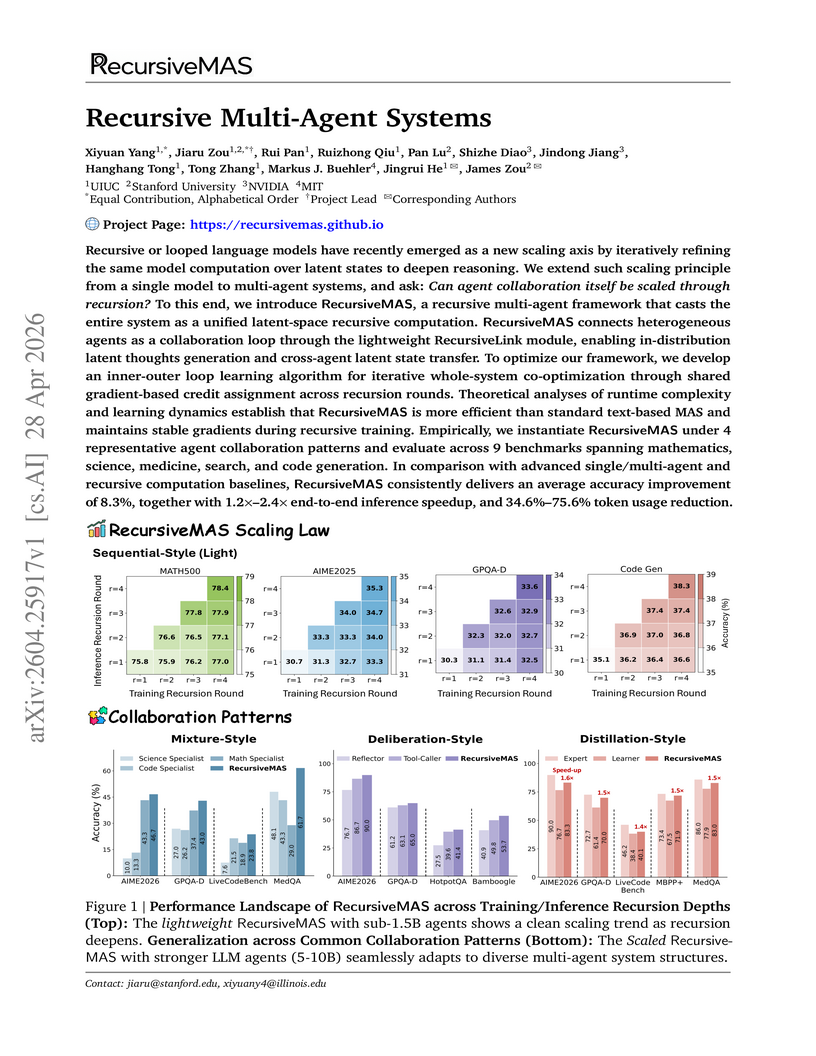
Xiyuan Yang, Jiaru Zou, Rui Pan
University of Illinois at Urbana-Champaign, Stanford University, NVIDIA, MIT

Haoquan Fang, Jiafei Duan, Donovan Clay
Allen Institute for AI, University of Washington, National University of Singapore, University of Pennsylvania, Johns Hopkins University, Amazon, Cortex AI, University of Michigan, University of North Carolina at Chapel Hill

Thinking Machines, Kevin Lu
Thinking Machines Lab

John Yang, Kilian Lieret, Jeffrey Ma
Meta FAIR, Meta TBD, Stanford University, Harvard University

Dongyoung Kim, Huiwon Jang, Myungkyu Koo
RLWRLD, KAIST
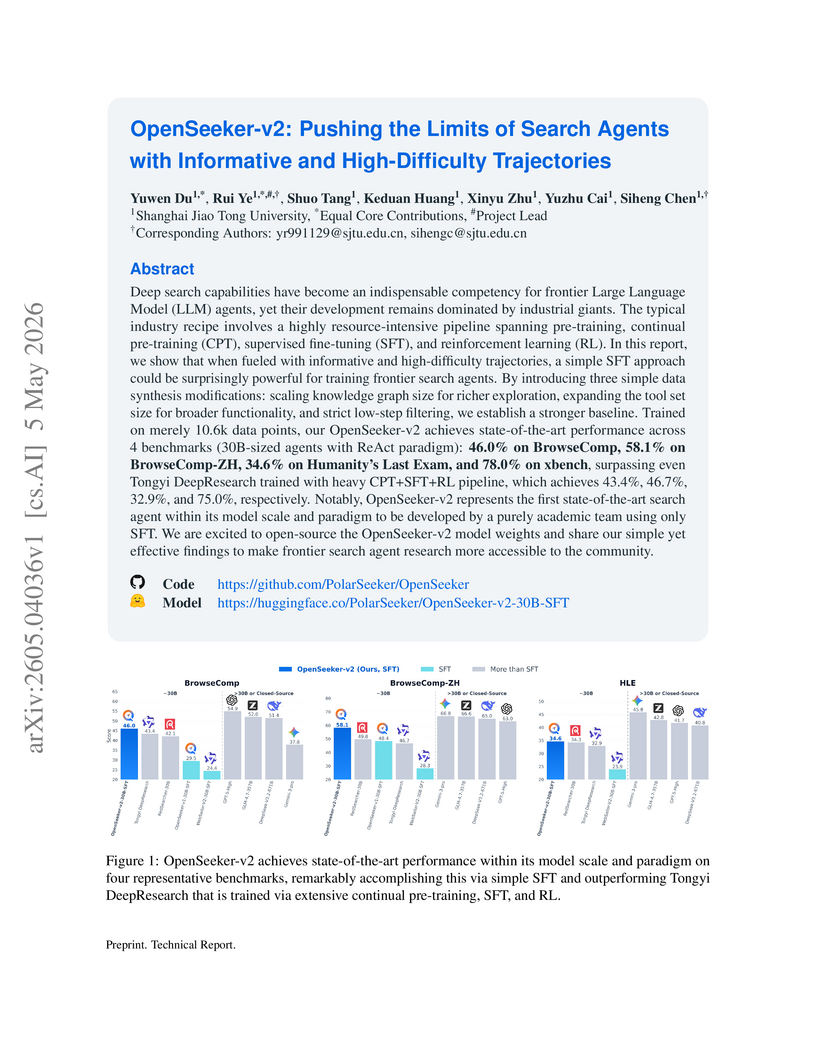
Yuwen Du, Rui Ye, Shuo Tang
Shanghai Jiao Tong University

Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr
The Chinese University of Hong Kong, Shanghai Artificial Intelligence Laboratory, University of Georgia, University of Oxford, Shenzhen Loop Area Institute

Ryan Wang, Akshita Bhagia, Sewon Min
University of California, Berkeley, Allen Institute for AI

Justin Lovelace, Christian Belardi, Srivatsa Kundurthy, Shriya Sudhakar, Kilian Q. Weinberger
Cornell University

Ilya Borovik
Skolkovo Institute of Science and Technology

Pranav Mantini, Shishir K. Shah
University of Houston, The University of Oklahoma

Yu-Cheng Lin, Yu-Chao Hsu, I-Shan Tsai, Chun-Hua Lin, Kuo-Chung Peng
National Yang Ming Chiao Tung University, National Center for High-Performance Computing, National Institutes of Applied Research, National Cheng Kung University, University of California, San Diego, National Taiwan University, NVIDIA AI Technology Center
System online.