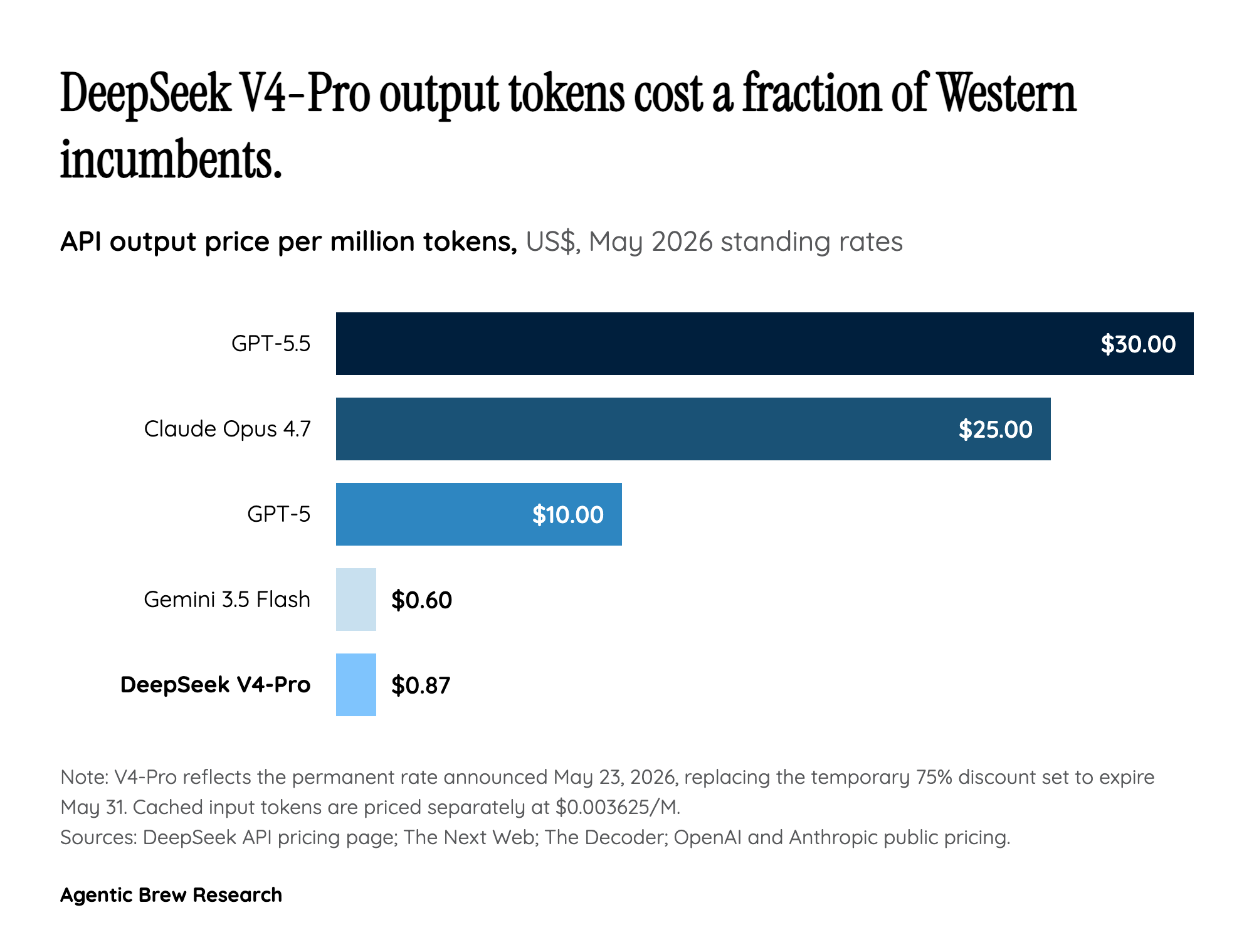
The Cache Discount Is the Real Number; the Headline Buries It
Most coverage led with the 75% figure, but the more consequential line in DeepSeek's pricing table is the cached-input rate: $0.003625 per million tokens, against $0.435 for non-cached input and $0.87 for output [1]. That is roughly a 120x discount on input bytes DeepSeek has already seen in a recent context window, and it reshapes the unit economics of any application that reuses a system prompt, a long retrieved document, or a stable codebase across many calls.
Practitioners are already running the math out loud. The dominant thread on r/DeepSeek and r/hermesagent is that real bills land far below what the headline price would imply once roughly 95% of input tokens hit the cache - one developer described feeding 6M input tokens plus 80K output tokens for about sixteen cents. The benchmark account Artificial Analysis framed the same point at a higher altitude, putting V4-Pro on the Pareto frontier of intelligence versus cost to run intelligence alongside V4 Flash [2].
The practical consequence is that the V4-Pro price sheet rewards a specific style of application - long-lived sessions, repeated prefixes, RAG with stable retrieval - and quietly penalizes one-shot, low-reuse calls where the cache never warms. Builders who treat V4-Pro as a drop-in for a model billed at a flat per-token rate will see the smaller discount; teams that re-architect prompts around persistent prefixes will see the larger one. The structural lesson for the rest of the industry is that the next round of frontier pricing competition will be fought on cache mechanics, not list prices.