Why OpenAI Built a Chip That Can't Train Anything
The most important thing to understand about Jalapeño is what it deliberately does not do. It is an inference-only ASIC, an application-specific integrated circuit purpose-built for one job: running already-trained models when a user types a prompt into ChatGPT, Codex, or the API [1]. It does not train models. OpenAI is expected to keep buying Nvidia GPUs for pre-training its largest models for the foreseeable future, because the most performance-intensive work still lives there [2]. That makes Jalapeño a selective carve-out rather than a clean break from Nvidia.
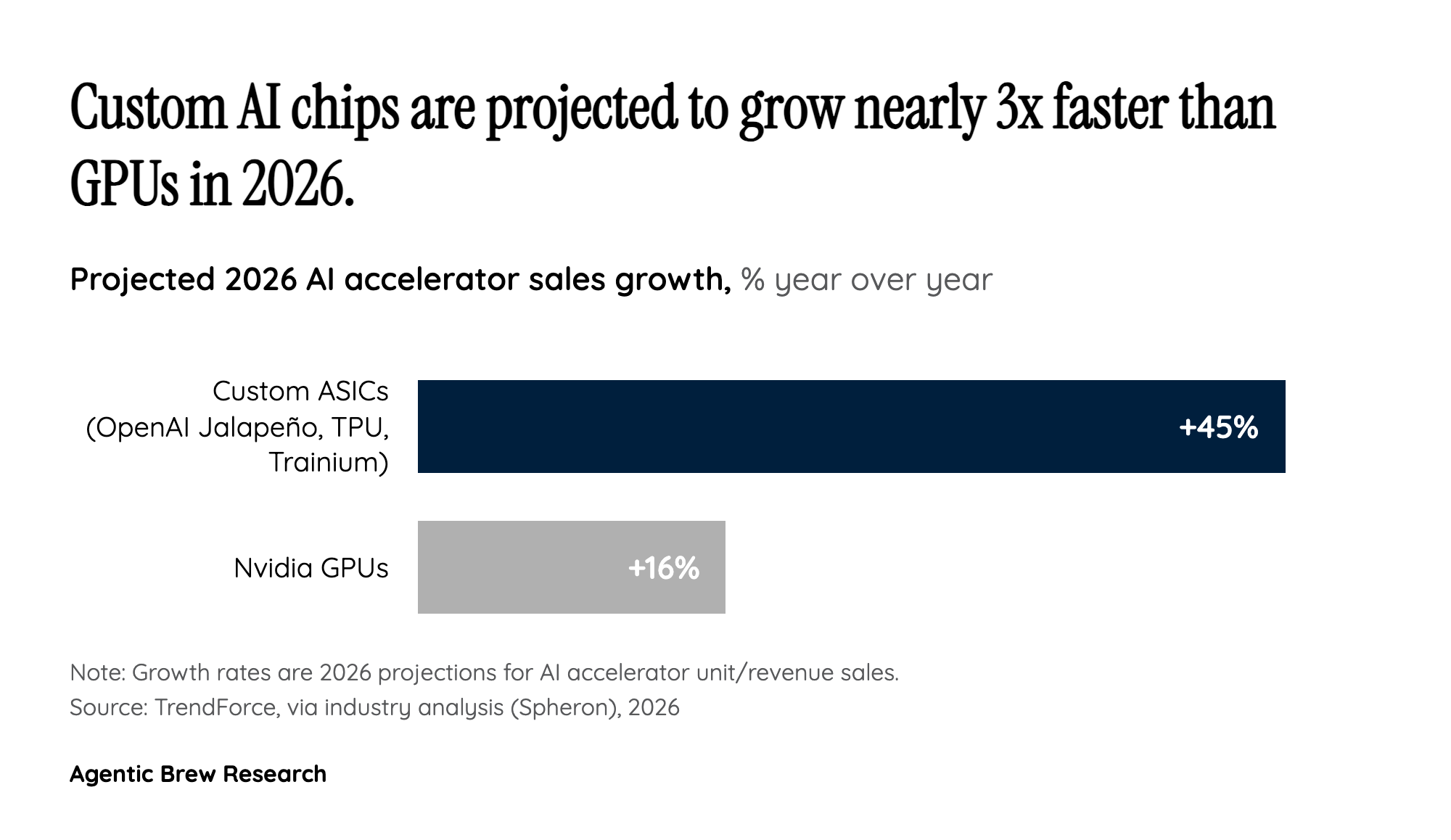
The logic is economic. Inference now represents roughly two-thirds of all AI compute, because a model is trained once but answered billions of times [3]. When the recurring cost of your business is serving tokens, shaving the cost of each token compounds. A general-purpose GPU is built to do many things well; a fixed-function ASIC built around your own kernels and serving systems can be co-optimized for latency, throughput, and cost on exactly the workloads you run. OpenAI President Greg Brockman framed the bet as hunting for 'specific workloads that are underserved' by general-purpose hardware [2]. The strategic prize, repeatedly described as an 'Apple-like' move, is vertical integration: by owning the chip, the memory, the networking, the scheduling, and the deployment, OpenAI can tune the whole stack together instead of renting someone else's silicon and accepting their tradeoffs [4].