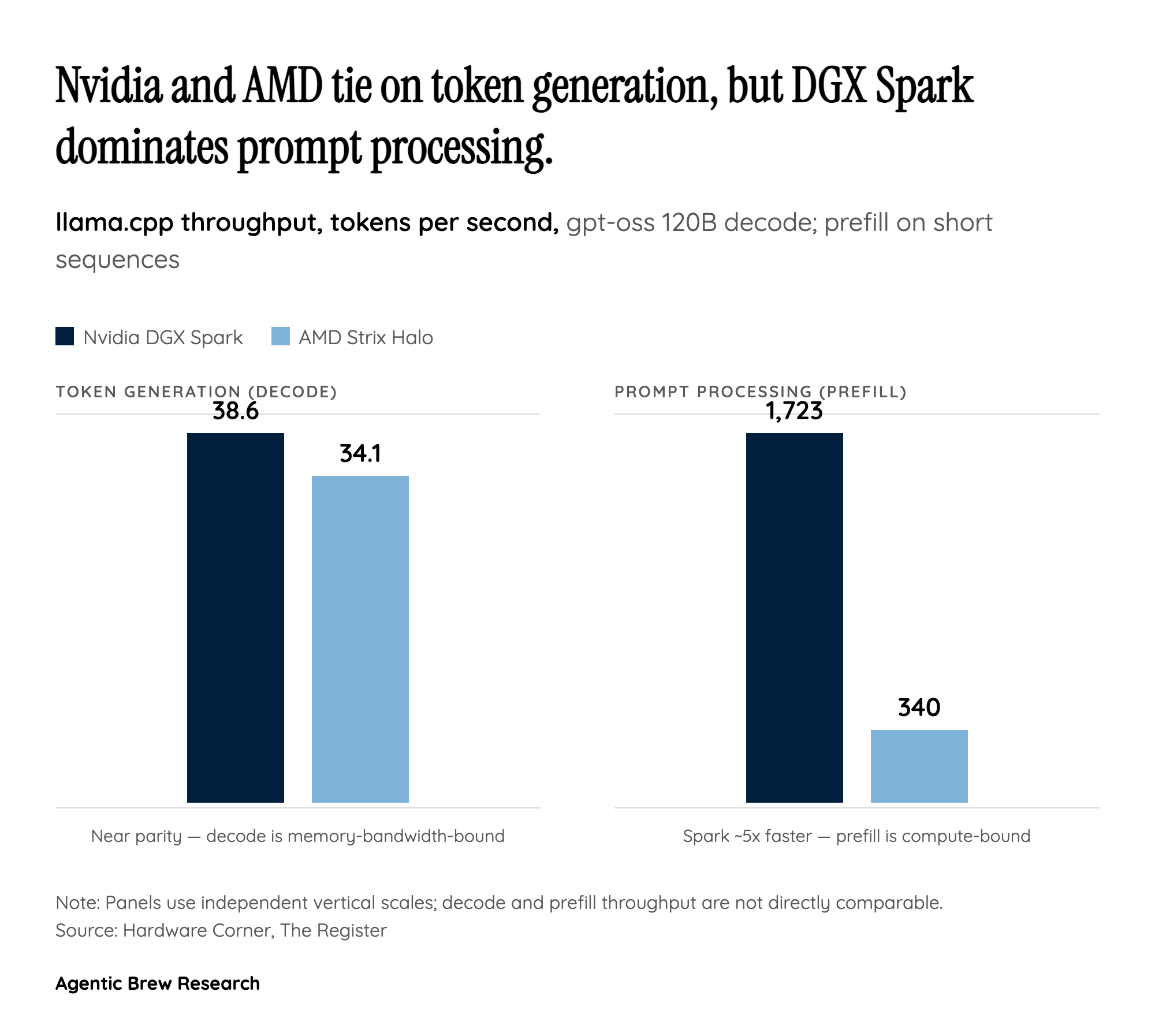
Under the Hood: Why a Half-Price Box Ties a $4,000 One
The headline shock of this matchup is that a Strix Halo mini PC starting around $1,499 generates LLM tokens at roughly the same speed as the $3,999 DGX Spark [6]. That is not a fluke. Single-batch LLM token generation (the decode phase, where the model emits one token at a time) is memory-bandwidth-bound, not compute-bound: every generated token requires streaming the model's weights through memory, so throughput is gated by how fast you can move bytes, not how many FLOPS you can do. The two boxes have nearly identical bandwidth, about 273 GB/s on the Spark versus 256 GB/s on the Strix Halo HP Z2 Mini G1a [2], so they 'churn out tokens at a similar pace' [1]. The benchmarks bear this out: on gpt-oss 120B the Spark hit ~38.6 tok/s versus ~34.1 on Strix Halo, and on a Llama 3.3 70B run the Strix Halo actually edged ahead at 4.97 versus 4.67 tok/s [4]. LMSYS measured the mechanism directly, calling the limited bandwidth 'the key bottleneck in AI inference' [2]. Nvidia's far larger compute budget (6,144 CUDA cores against the Radeon 8060S's 40 CUs / 2,560 stream processors) simply has nothing to do during decode [1].