The Rollout Paradox: Open-Frontier Rhetoric, Paywalled and Throttled
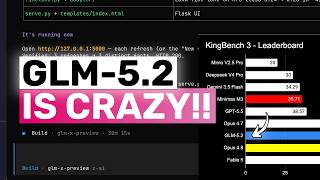
GLM-5.2's launch messaging leans hard on radical openness — frontier intelligence that should be open, usable, and buildable, with MIT-licensed weights promised for the following week [5]. Yet on launch day the only way to touch the model was a paid GLM Coding Plan subscription, with no standalone API and no public chatbot until the next week [2]. That gap is the central tension. The model is treated as an advanced, premium-quota system: reportedly 3x the standard consumption rate at peak hours and 2x off-peak, so even paying users burn their allowance fast [6]. Coding Plan quotas are tiered — roughly 80 prompts per 5 hours on Lite, 400 on Pro, and 1,600 on Max, with Team seats managed separately [1].
That contradiction is what the community fixated on. Independent testers and commentators reported severe first-party throttling on launch day, and one analyst directly questioned the economics of a plan where the heaviest users appear to be penalized rather than rewarded. The result: a model marketed as accessible, open frontier intelligence that, for its first week, was gated, metered, and prone to slowing under load — with many users explicitly planning to wait for the open weights and run GLM-5.2 through third-party providers instead.