Under the Hood: The Four Moves That Replaced Prompt Engineering
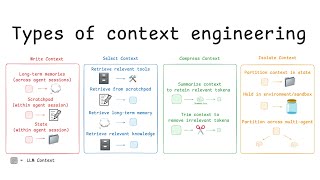
The cleanest way to read this whole moment is through LangChain's four-verb framework. Context, they argue, can only be written (saved outside the window), selected (pulled back in when relevant), compressed (kept only as the tokens you actually need), or isolated (split across sub-agents) [1]. That tiny taxonomy is doing a lot of work, because every harness pattern shipping in 2025 and 2026 is some specific combination of those four moves.
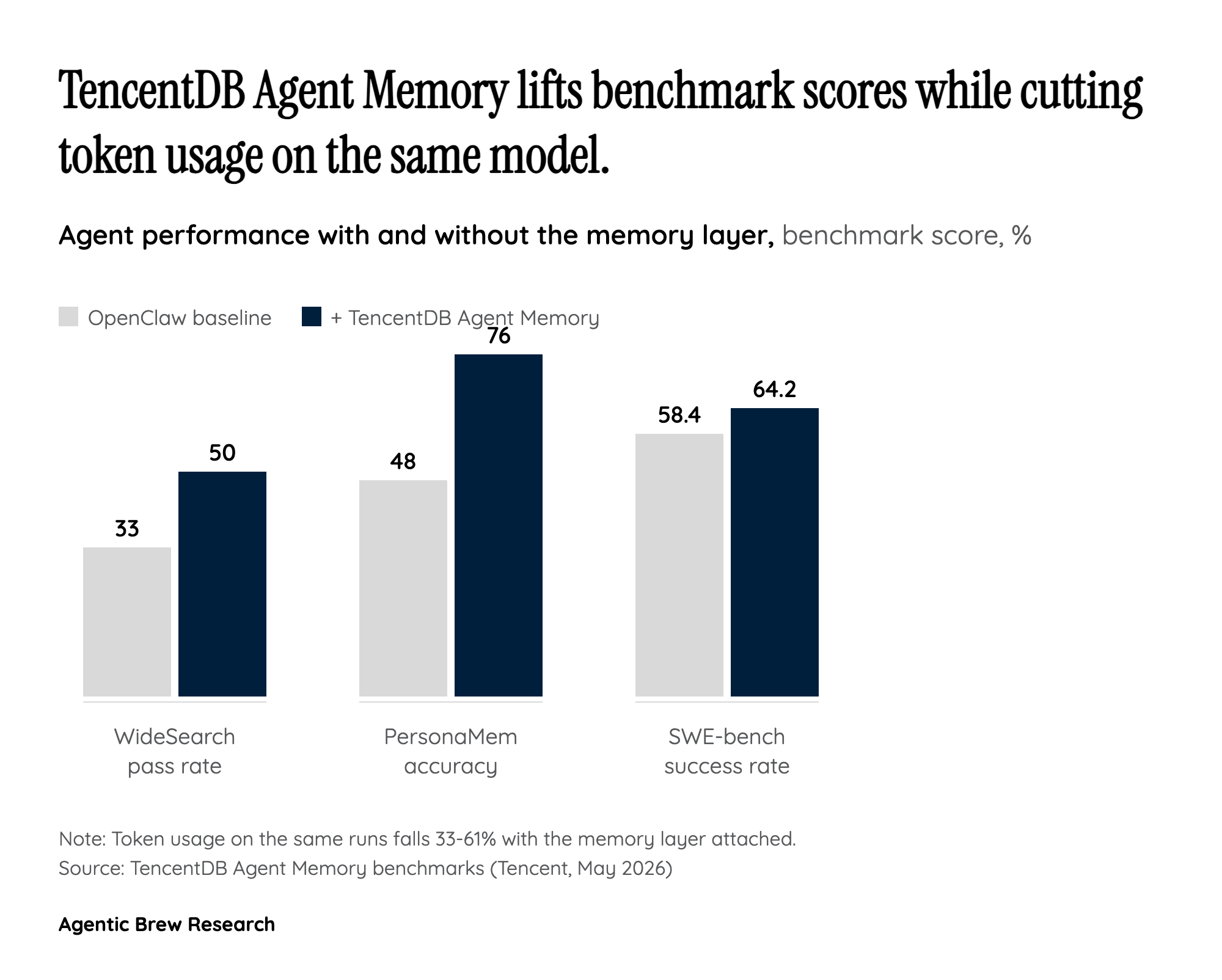
TencentDB Agent Memory is the most literal implementation. Its four tiers (L0 conversation, L1 atom, L2 scenario, L3 persona) correspond to raw dialogue, atomic facts, scene blocks, and a user profile [2]. Full tool logs are written out to refs/*.md files, and live task state is encoded in Mermaid task canvases the agent re-reads instead of carrying a giant transcript. That is write plus compress, made operational. Anthropic's long-running coding harness does the same trick with cruder tools: an initializer agent that sets up the environment on the first run, and a coding agent that makes incremental progress, communicating through a claude-progress.txt artifact and git history because, in their words, context windows are limited and agents need a way to bridge the gap between coding sessions [3].
The Natural-Language Agent Harnesses paper from Pan et al. pushes the same logic up a level. Instead of letting these write/select/compress/isolate choices live inside opaque code, NLAHs are editable documents that describe run-level harness policy, and an Intelligent Harness Runtime interprets those documents into agent calls, handoffs, state updates, validation gates, and artifact contracts [4]. The harness itself becomes a piece of context, written in language, that any reviewer can read.