From Prompt Engineering to Context Engineering: The Vocabulary Shift That Actually Means Something
The renaming of the discipline from prompt engineering to context engineering was not a marketing tweak, it was a tacit admission that the bottleneck in production LLM systems is no longer how you phrase one instruction but which tokens you let into the window in the first place. Anthropic's own engineering post is unusually blunt about this: good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome [2]. Andrej Karpathy and Tobi Lutke both reached the same conclusion independently in June 2025, and Simon Willison's consolidation piece is where the term locked in for the broader developer community [5].
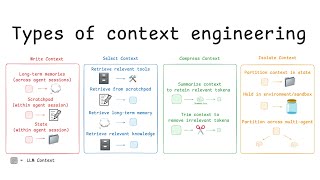
The deeper reason it stuck is that the practice it names is genuinely different. Prompt engineering treats the model like a function and asks how to word the argument. Context engineering treats the agent as a system that runs across many turns and asks which artifacts, tools, retrieved documents, prior tool outputs and reasoning traces should occupy a finite window at each step. The LangChain ecosystem has since anchored on a working frame of four canonical strategies — Write, Select, Compress and Isolate — which has become the community's de-facto teaching vocabulary. Practitioners on r/PromptEngineering have started formalizing the same work into a 5-stage pipeline (Curate / Compress / Structure / Deliver / Refresh) plus a tiered memory budget split roughly into working context (60-70%), recent compressed history (20-30%) and always-true facts (10-15%). Failure modes have names now too, including 'context rot,' the gradual degradation of agent quality as stale or low-signal tokens accumulate across turns.
The primary versus secondary source metaphor that seeded this cluster makes the heuristic operational: raw data, transcripts and code are primary, summaries and documentation are secondary, and a well-engineered context preserves the primary material when fidelity matters. Anthropic extends the same discipline to multi-agent systems, arguing that sub-agents should communicate through artifacts rather than raw traces, so a web-search agent surfaces only material the downstream agent can actually use rather than dumping its full browsing history [2].