Compute Laundering Through Cognition
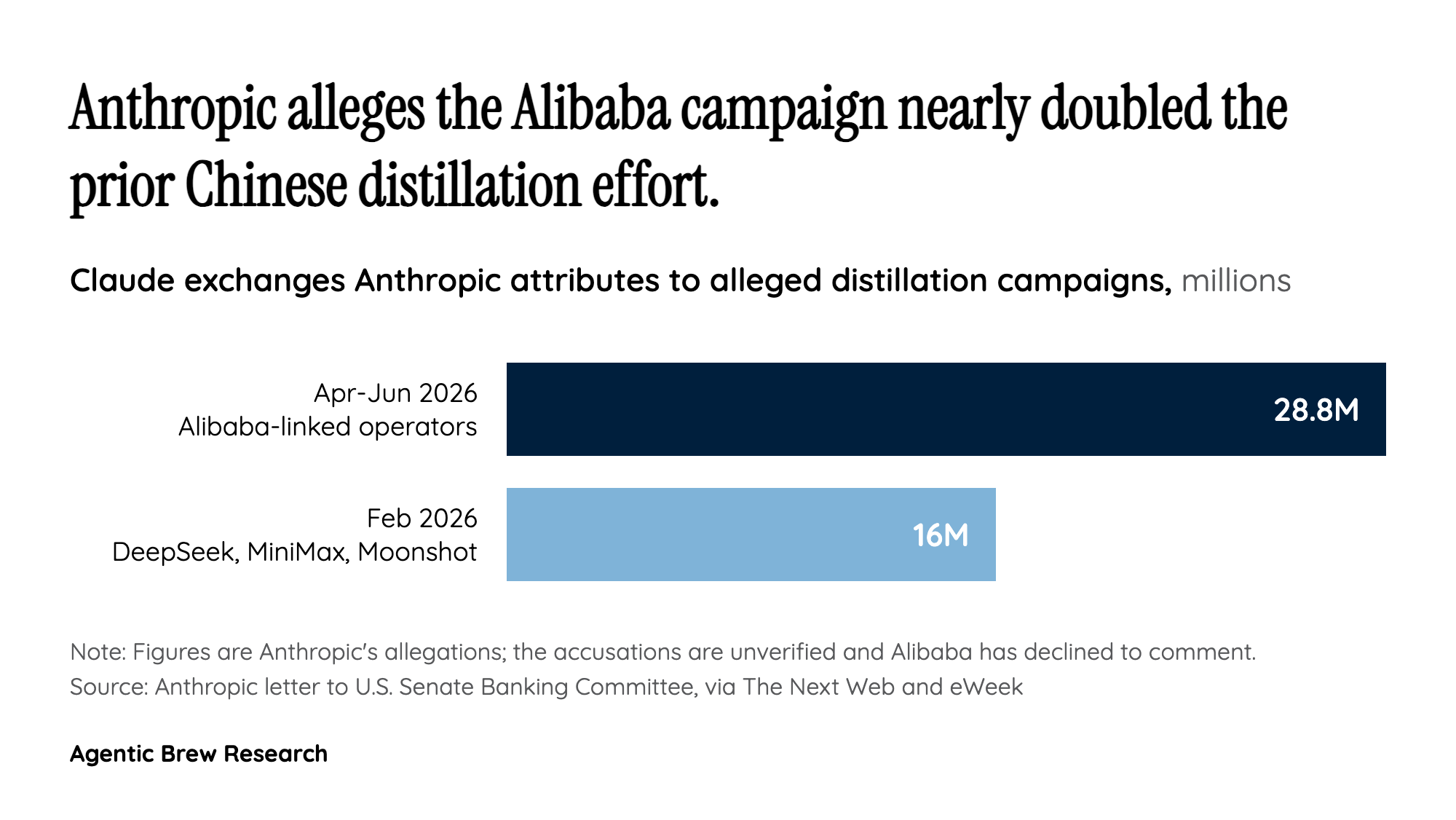
The reason this accusation matters far beyond one corporate grievance is the mechanism behind it. Distillation is the practice of copying a model's behavior by querying it at scale and training a smaller model on its answers - no source code, no model weights, and no breached servers are involved. In Anthropic's telling, operators linked to Alibaba generated roughly 28.8 million exchanges with Claude using nearly 25,000 fraudulent accounts over about six weeks [1], deliberately steering the queries toward Claude's most commercially valuable capabilities, software engineering and agentic reasoning [2]. One industry analysis estimates that volume of conversation could yield on the order of 14.4 billion tokens of teacher output [1]- effectively a training corpus assembled one prompt at a time.
The strategic punchline is that this route sidesteps the entire architecture of U.S. export controls. Those rules govern the sale of advanced chips and model weights; they say nothing about asking a publicly available model a few million questions. As one commentary put it, current controls focus on hardware and model weights, but distillation extracts capability through API access alone [1]. Anthropic says the operators even used commercial proxy services to evade the geographic restrictions that bar Chinese entities from Claude [4]. If you think of frontier capability as something that normally requires enormous compute to create, distillation is a way to import that capability as finished cognition rather than as regulated silicon - compute laundering through the API.


