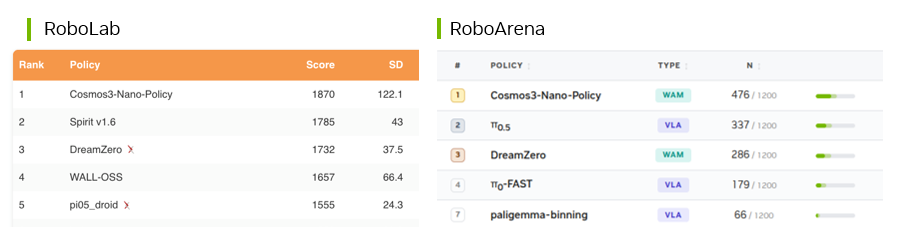
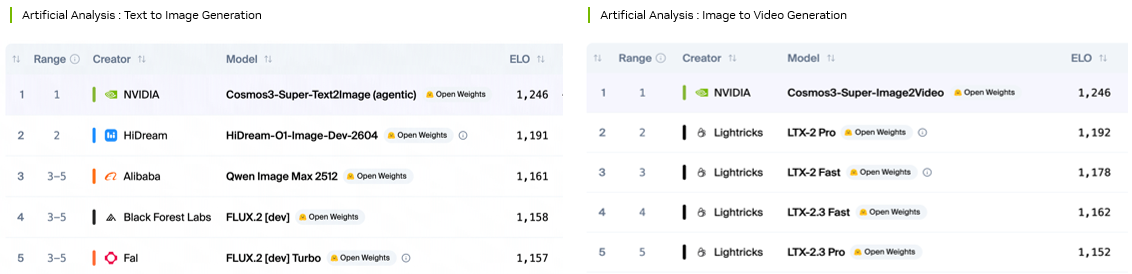
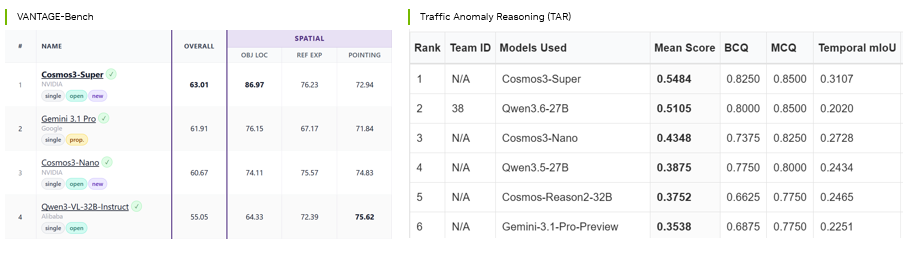
One model, two transformers: how Cosmos 3 collapses perception and generation
The defining mechanism in Cosmos 3 is a mixture-of-transformers (MoT) layout that pairs a reasoning transformer with an expert generation transformer inside a single forward pass. The reasoner first parses a scene — object interactions, motion, spatial-temporal relationships — and only then hands a structured representation to the generator, which emits the next video frames, audio, or robot action trajectory [1]. NVIDIA frames this as the difference between a model that 'understands what matters' and a model that merely paints plausible pixels, a distinction Rev Lebaredian stresses when he calls Cosmos 3 a 'physically accurate simulation' that predicts what happens next and generates actions [10].
In the Cosmos 2 generation, perception (Reason) and generation (Predict, Transfer) lived in separate models that had to be stitched together by application code. Cosmos 3 collapses that pipeline into one omnimodel that natively spans text, image, video, ambient sound, and action [2]. The practical payoff is fewer integration seams between the model that 'sees' and the model that 'acts,' which is what robotics teams need when they ask a foundation model to close the loop from camera input to motor command. NVIDIA argues this is what cuts training and evaluation cycles 'from months to days' for downstream Physical AI teams [1].