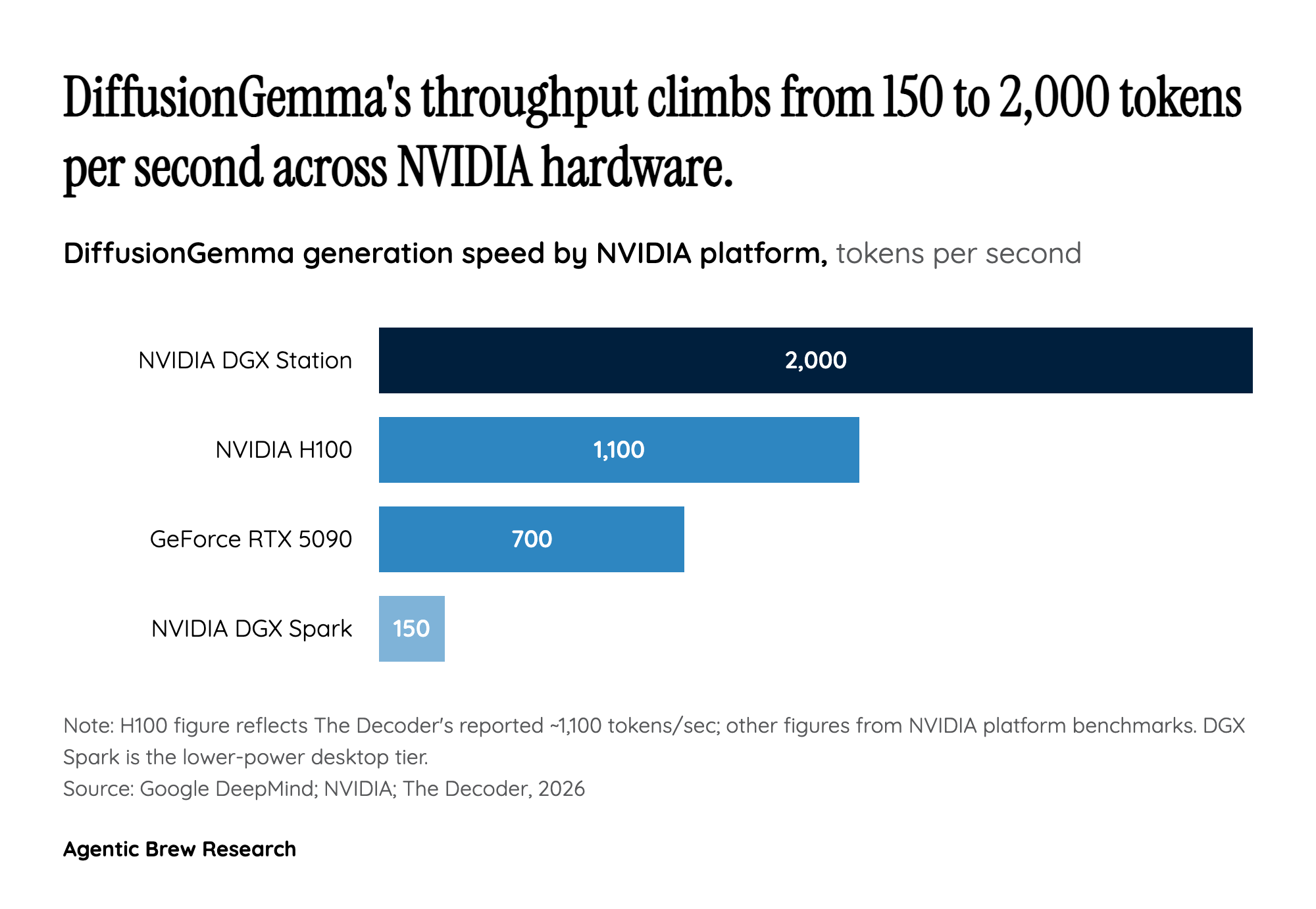
Denoising a paragraph instead of typing it: how text diffusion actually works
Every mainstream large language model since GPT has written the same way a person types: one token at a time, left to right, each word conditioned on the words already committed. DiffusionGemma throws that out. Instead of predicting the next word, it drafts an entire 256-token paragraph simultaneously and then refines it [1]. The process borrows directly from image diffusion. The model starts with a block of 256 random placeholder tokens and refines them across several passes until readable text emerges [5], running up to roughly 48 denoising steps and resolving on the order of 15 to 20 tokens per forward pass [6].
The architectural unlock that makes this work is bi-directional attention. In an autoregressive model, a token can only see what came before it. In DiffusionGemma, each token can reference every other token during generation, including ones that come later [5]. That single property is the source of nearly every interesting behavior the model has, from self-correction to fill-in-the-middle editing. Under the hood it remains a Gemma 4 model: a 26B-parameter Mixture-of-Experts that activates roughly 3.8B parameters, firing 8 of its 128 experts per pass, with a 256K context window and a 262K-token vocabulary trained across 140-plus languages [4]. The diffusion head is grafted onto that proven backbone rather than trained from scratch, which is why Google can ship it as an open Gemma sibling rather than a wholly new research artifact.