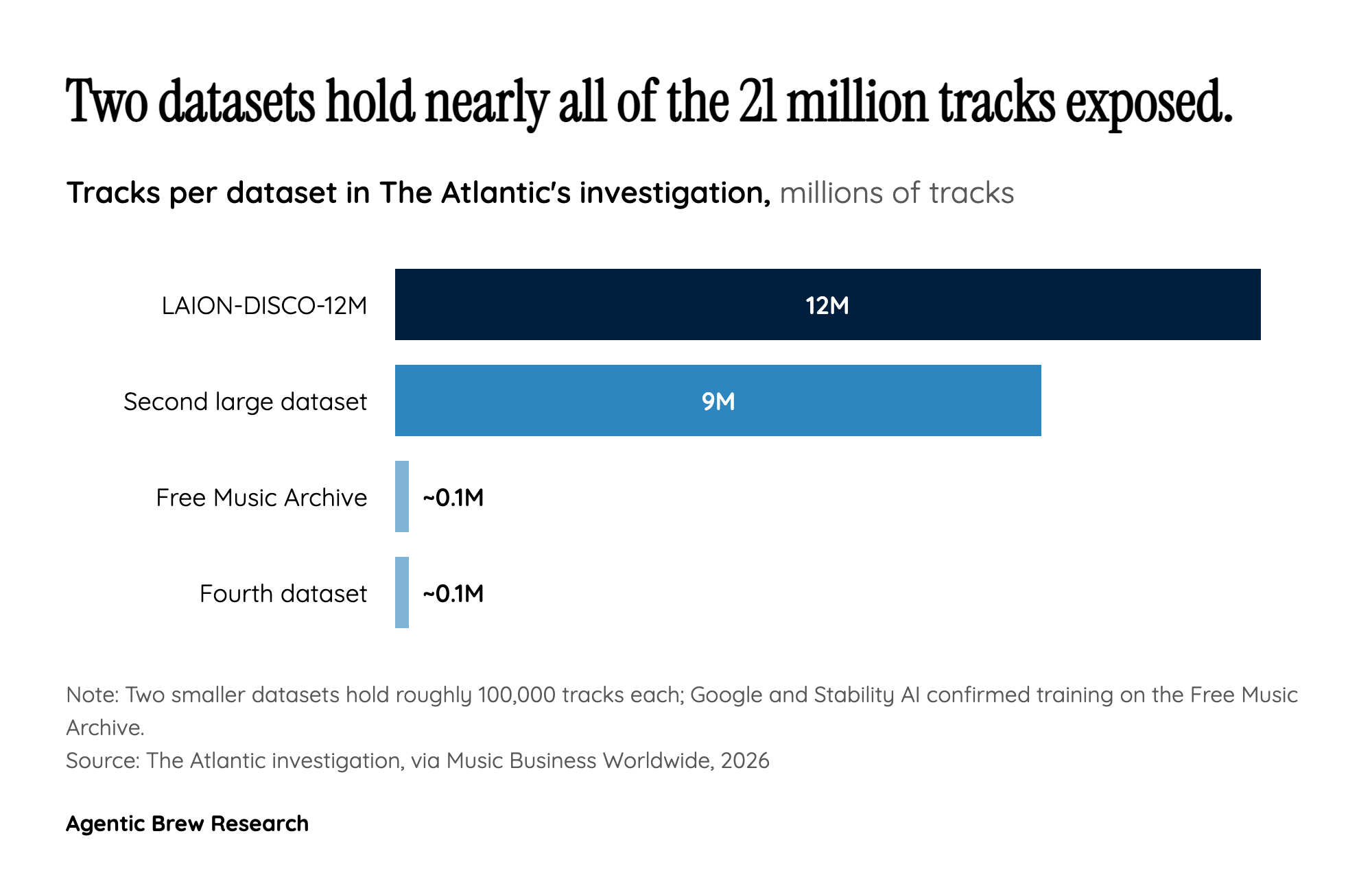
The 'Research Only' Label That Holds 21 Million Songs
The most revealing detail in The Atlantic's investigation is not the size of the datasets but how innocuous their packaging is. The largest, LAION-DISCO-12M, was released in November 2024 by LAION, a German non-profit, and contains no actual audio files at all [1]. It is a manifest: 12+ million links to YouTube tracks plus metadata, explicitly published "for research purposes" and intended for use "in academic settings" [1]. The Free Music Archive, one of the two smaller ~100,000-track collections, follows the same template — assembled in 2017 by academic researchers for music-information-retrieval work, directed by the radio station WFMU, and built on Creative Commons licenses [1].
That framing is the entire problem. A dataset that is technically just a list of URLs and a stack of CC-tagged files looks harmless on a project page, but it is a turnkey ingestion pipeline for anyone training a model. The Atlantic's reporting shows the gap between the stated intent (academic study) and the actual use (commercial music generation) is where the consent of millions of artists evaporated [2]. The non-profit can say "don't deploy this commercially" and the developer can quietly do exactly that, because nothing in the dataset's structure enforces the boundary. The reporting also stresses a hard limit of the evidence: the tool can show which songs sit inside a dataset, but not which specific company pulled them out [3].