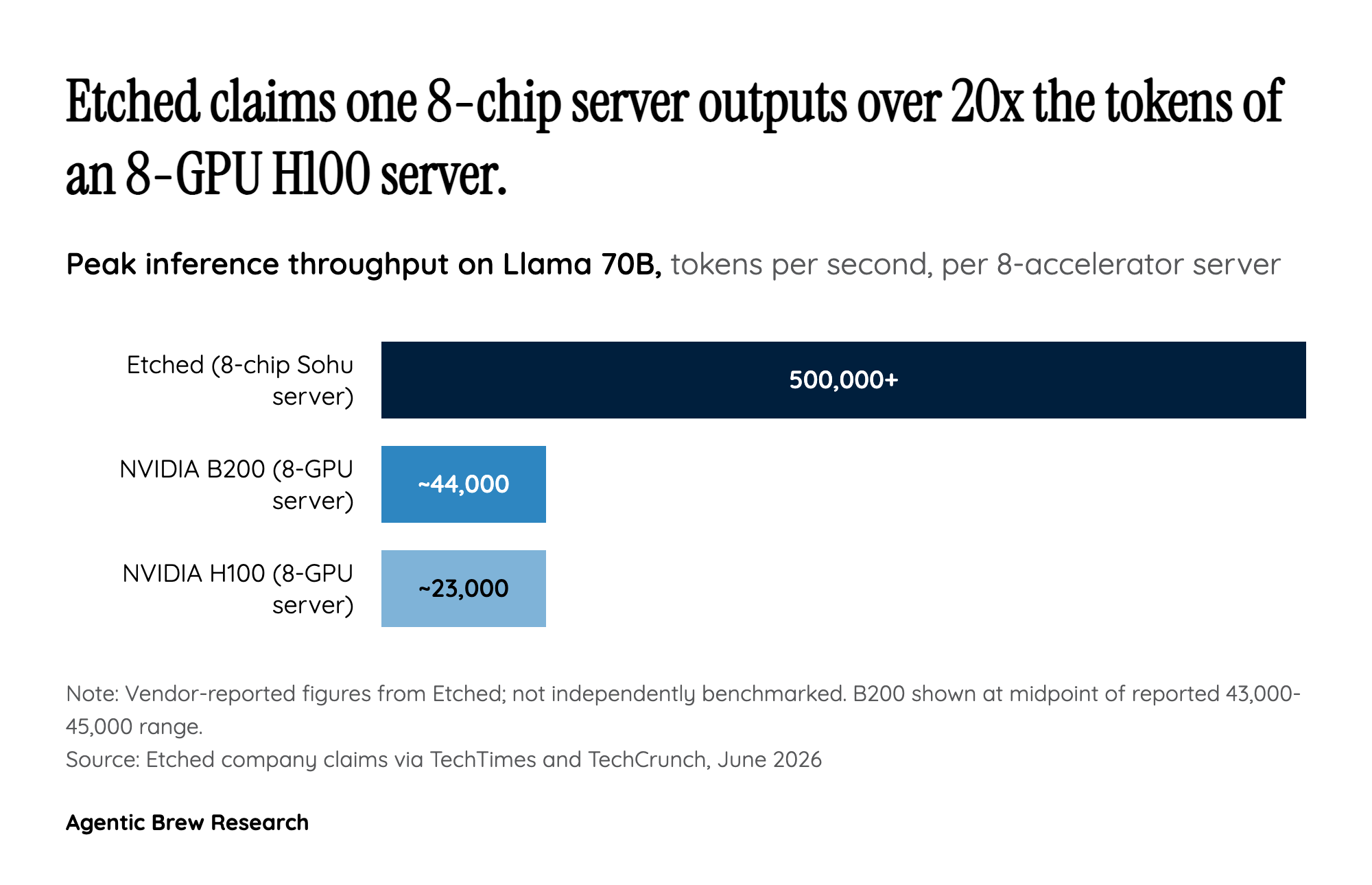
Etching the Model Into the Metal
Most AI accelerators, including NVIDIA's GPUs, are general-purpose: the transformer architecture that powers modern language models runs as software on top of flexible compute cores. Etched inverts that. Its chip hard-codes transformer attention directly into silicon as fixed-function logic rather than running it as software on a programmable compute unit [4]. The bet is that when one architecture dominates a workload, you can strip out everything that makes a chip flexible and spend all of that transistor budget on doing the one thing faster and cheaper.
The founders frame this as history repeating: specialized hardware displaces general-purpose alternatives when there is a dominant, stable workload, in this case transformer inference [3]. That is the same logic that let purpose-built mining ASICs push GPUs out of cryptocurrency mining. The physical result is a rack-scale system rather than a bare chip - Etched sells complete inference clusters with custom racks and software [2], manufactured by TSMC on its N4P process with first-pass silicon success and 144 GB of HBM3E memory per die [1]. First-pass success matters because chip startups routinely burn a year and millions of dollars on silicon that comes back broken; getting it right on the first tapeout is a genuine engineering signal, not just a marketing line.