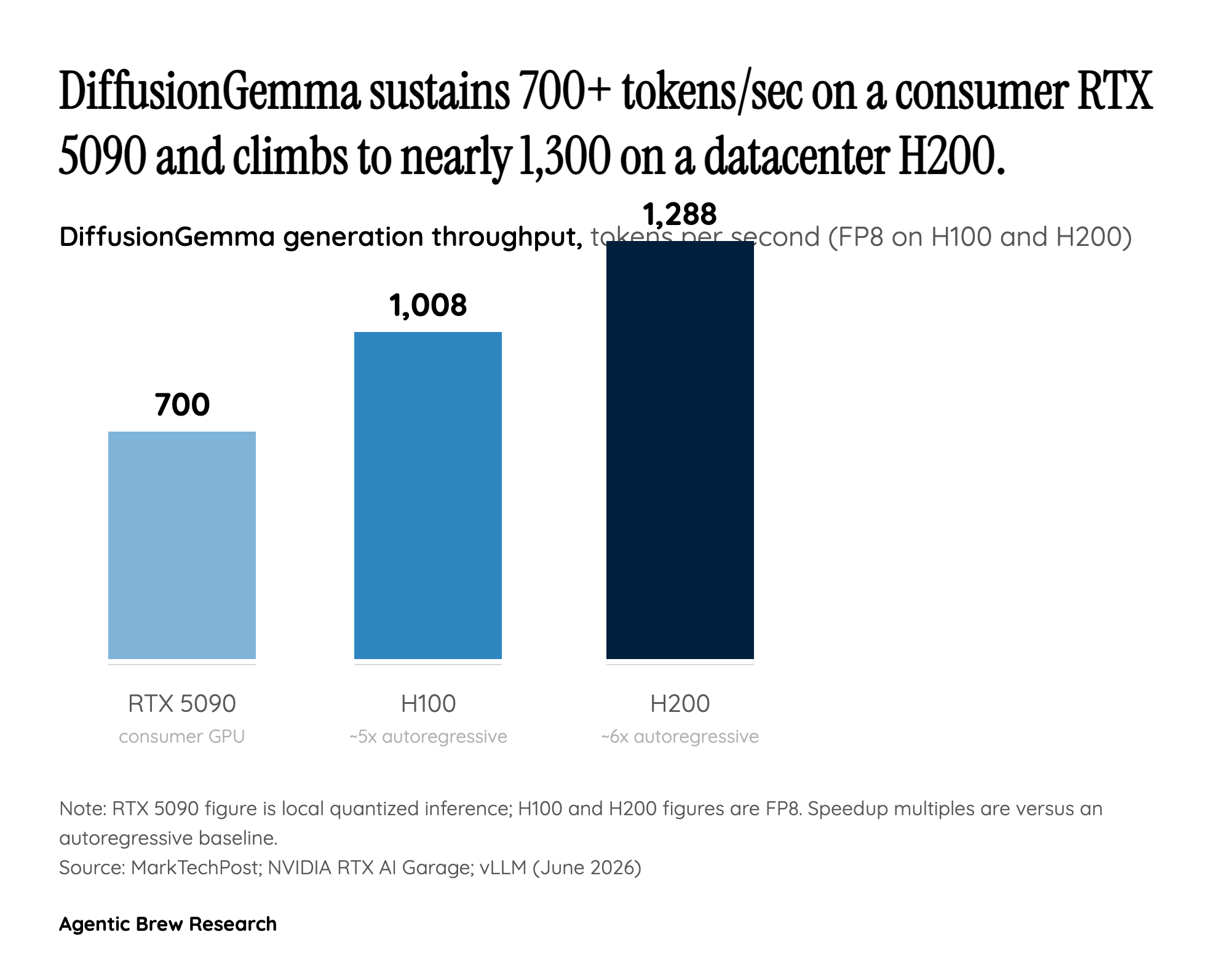
How it works: denoising a 256-token canvas instead of guessing one token at a time
DiffusionGemma abandons the autoregressive loop that every mainstream LLM uses. Instead of predicting the next token conditioned on everything before it, the model starts each block with a canvas of random placeholder tokens and iteratively locks in confident tokens until the whole block snaps into focus, 256 tokens per forward pass [1]. It denoises up to 256 tokens per step rather than emitting one at a time [2], locking roughly 15-20 tokens per forward pass and refining the rest across iterations [3].
The architecture is a hybrid: diffusion within each block, autoregressive across blocks. The decisive property is bidirectional attention. Because the model sees the whole canvas at once, it generates entire paragraphs rather than individual, next-token guesses, ensuring global logical consistency [3], and it can self-correct, revising tokens it placed earlier in the same block. That same global view is what makes it natively suited to non-linear tasks like in-line editing and code infilling, where an autoregressive model would have to regenerate from the edit point forward. The model card frames the shift as moving from token-by-token autoregression to block-autoregressive multi-canvas sampling [4].