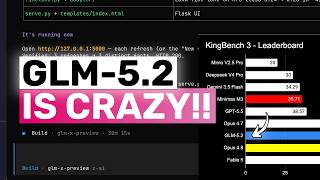
The open-weights gap to frontier closed models just collapsed

GLM-5.2's headline achievement is not that it wins a benchmark outright, but how close it gets to the frontier while remaining downloadable. It tops the Artificial Analysis Intelligence Index v4.1 at 51, the leading open-weights model by a wide margin over MiniMax-M3 (44), DeepSeek V4 Pro max (44), and Kimi K2.6 (43) [2]. On long-horizon coding the picture is even sharper: 74.4% on FrontierSWE places it within roughly one point of Claude Opus 4.8 (75.1%) and just above GPT-5.5 (72.6%), while Terminal-Bench 2.1 jumped to 81.0 from GLM-5.1's 63.5 [1].
The economic argument is what makes the benchmark argument matter. At $1.40 input and $4.40 output per 1M tokens on OpenRouter, GLM-5.2 runs roughly 9x cheaper than GPT-5.5 and about 8x cheaper than Opus, and Artificial Analysis pegs the cost at about $0.46 per Intelligence Index task [2][4]. Independent benchmark coverage found the model beats GPT-5.5 on multiple long-horizon coding benchmarks for a fraction of the cost [8]. The contrarian footnote from practitioners: GLM-5.2 is token-inefficient, spending around 43k output tokens per task, but at this price the verbosity is cheap.