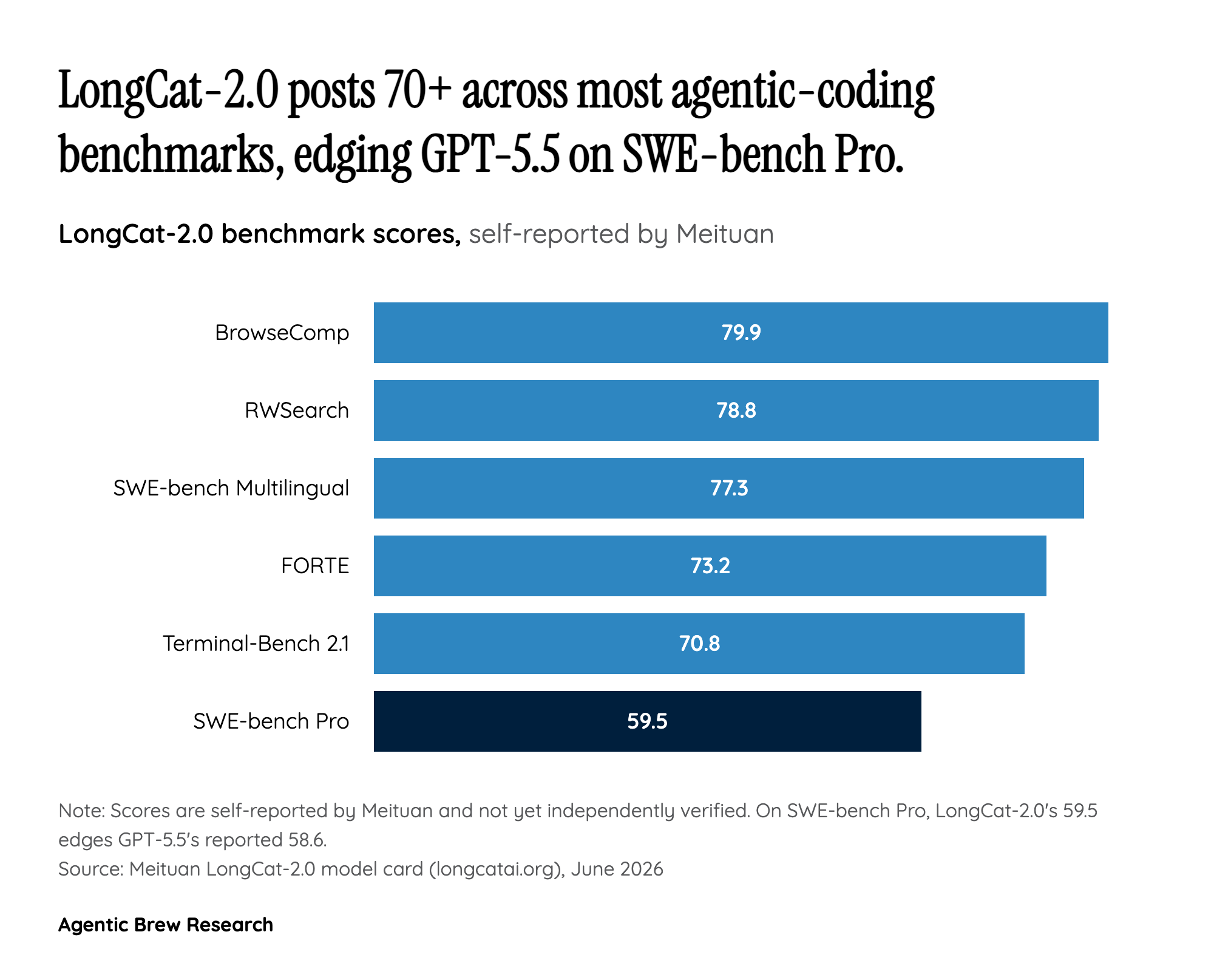
Beijing Cracked the One Wall That Actually Mattered
Meituan says LongCat-2.0 is the first trillion-parameter model to complete both full training and inference on a 50,000-card domestic Chinese compute cluster [1]. That phrase - full training - is the whole story. Until now, Chinese labs could run finished models on home-grown silicon, but the punishing pre-training run, the part that needs tens of thousands of chips talking to each other for weeks, was assumed to require Nvidia hardware [2]. To coordinate that many accelerators without Nvidia's NCCL networking layer, Meituan swapped in Huawei's HCCL communication library [3], and community teardowns peg the hardware as Huawei Ascend-class ASIC superpods.
The architecture is what makes the scale affordable. LongCat-2.0 is a sparse mixture-of-experts design: 1.6 trillion total parameters, but only about 48 billion fire on any given token, paired with a new 'LongCat Sparse Attention' that keeps the 1-million-token context window from exploding in cost [4]. The point is not that the chips beat Nvidia's - they do not - it is that 'good enough' domestic silicon, wired together cleverly, was enough to train a frontier-scale model start to finish. That is the exact assumption the entire export-control strategy was built to prevent.