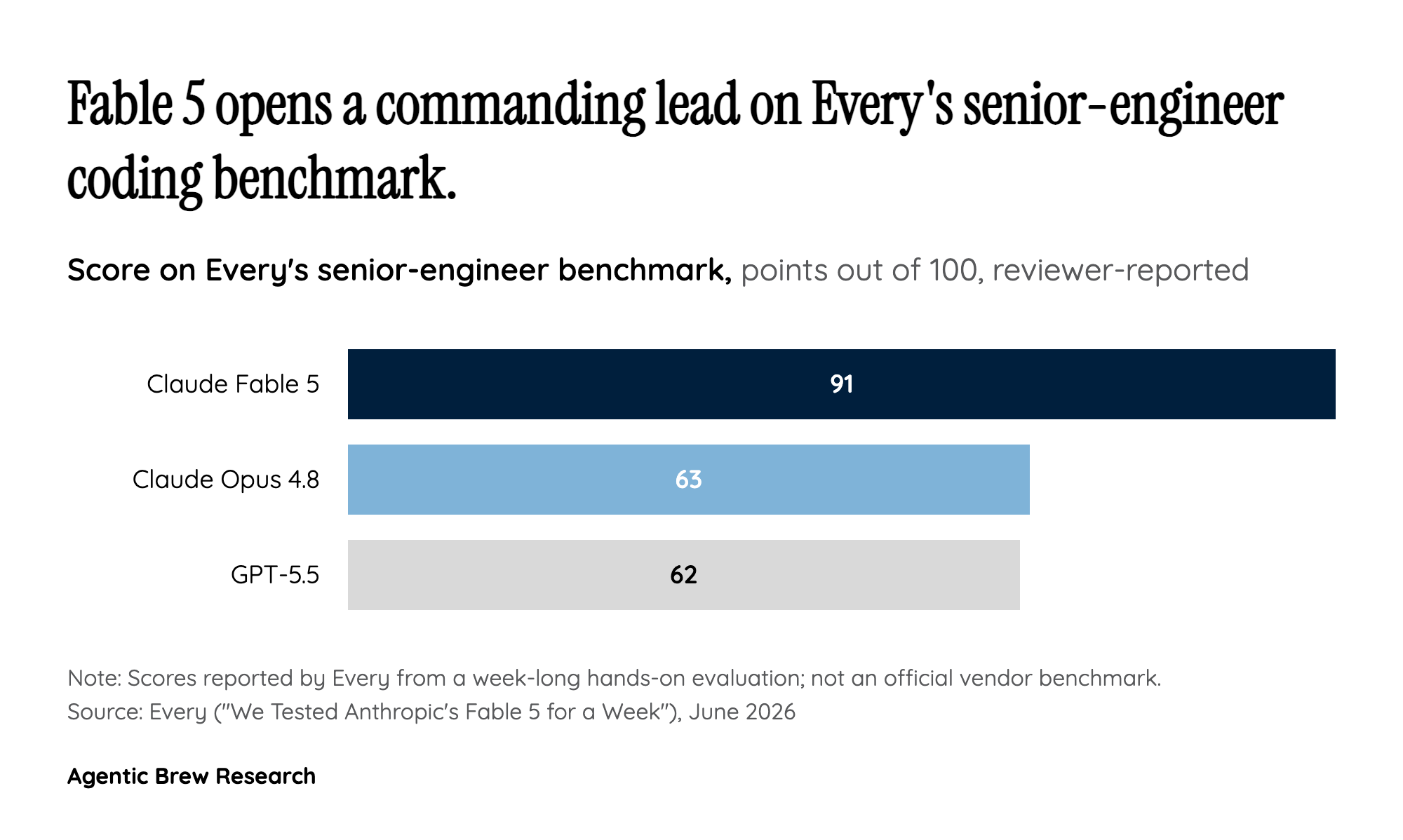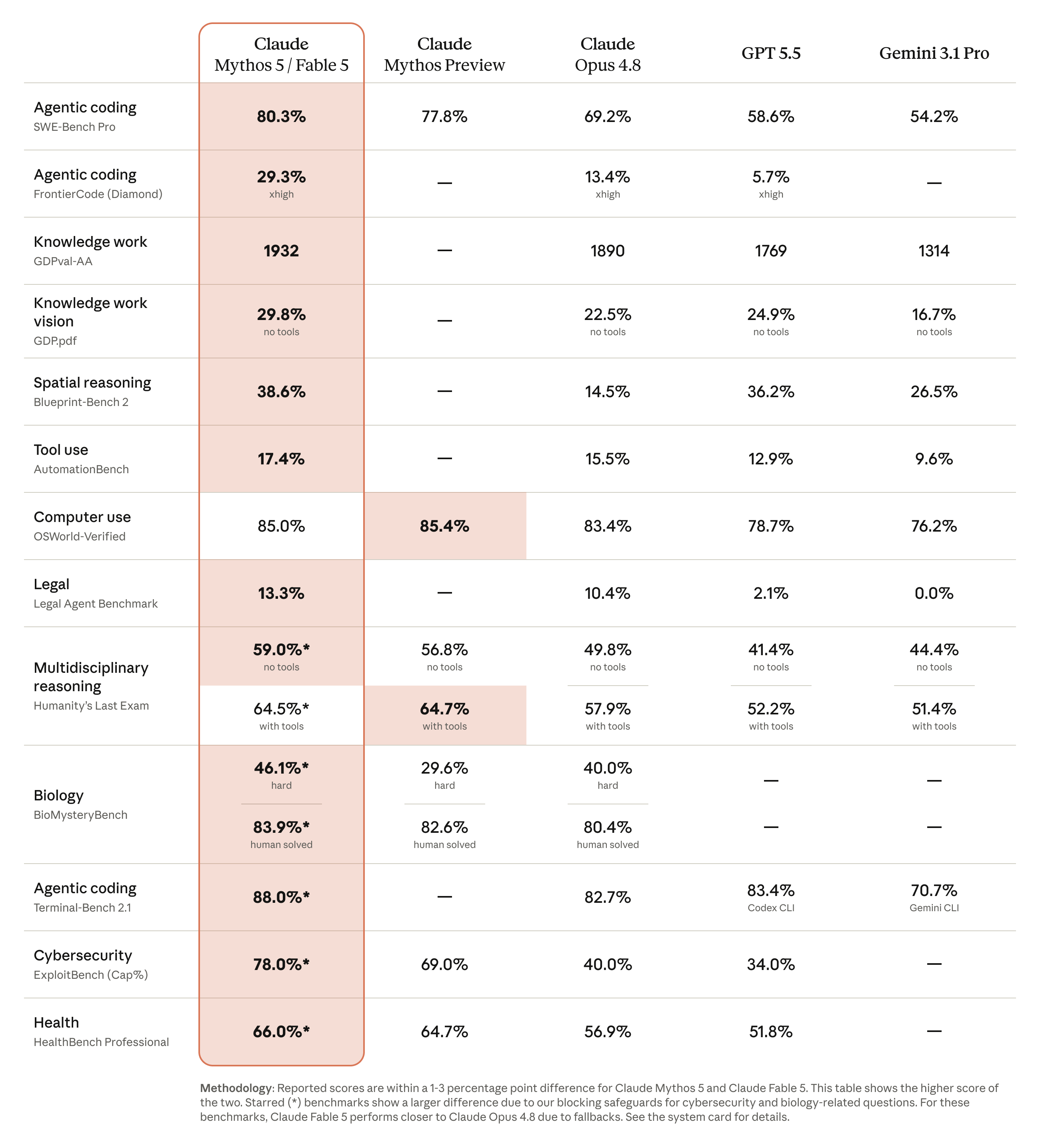
When Everyone Ships at Once, Speed Stops Being a Moat
The defining feature of summer 2026 is not any single model but the calendar. FourWeekMBA calls it the most compressed frontier release window in AI history, with six frontier models in flight and the best-model crown contested across five labs in a single quarter [4]. That cadence rewrites the competitive logic. When labs update flagship models every few weeks rather than every several months, release velocity itself becomes a barrier - but it also means no lab can hold a lead long enough to make it a moat. The analyst framing is blunt: this is 'the first period where multiple frontier models coexist at near-parity' [4], not a single breakthrough moment. Cheap training compounds the squeeze. DeepSeek's V4-Pro, reportedly a 1.6 trillion-parameter model trained on Huawei Ascend chips rather than NVIDIA, demonstrates frontier capability without the assumed hardware floor, and that collapses the cost assumptions every Western lab priced against [4]. With capability clustered within a few points on benchmarks, the contest moves downstream to distribution and price.