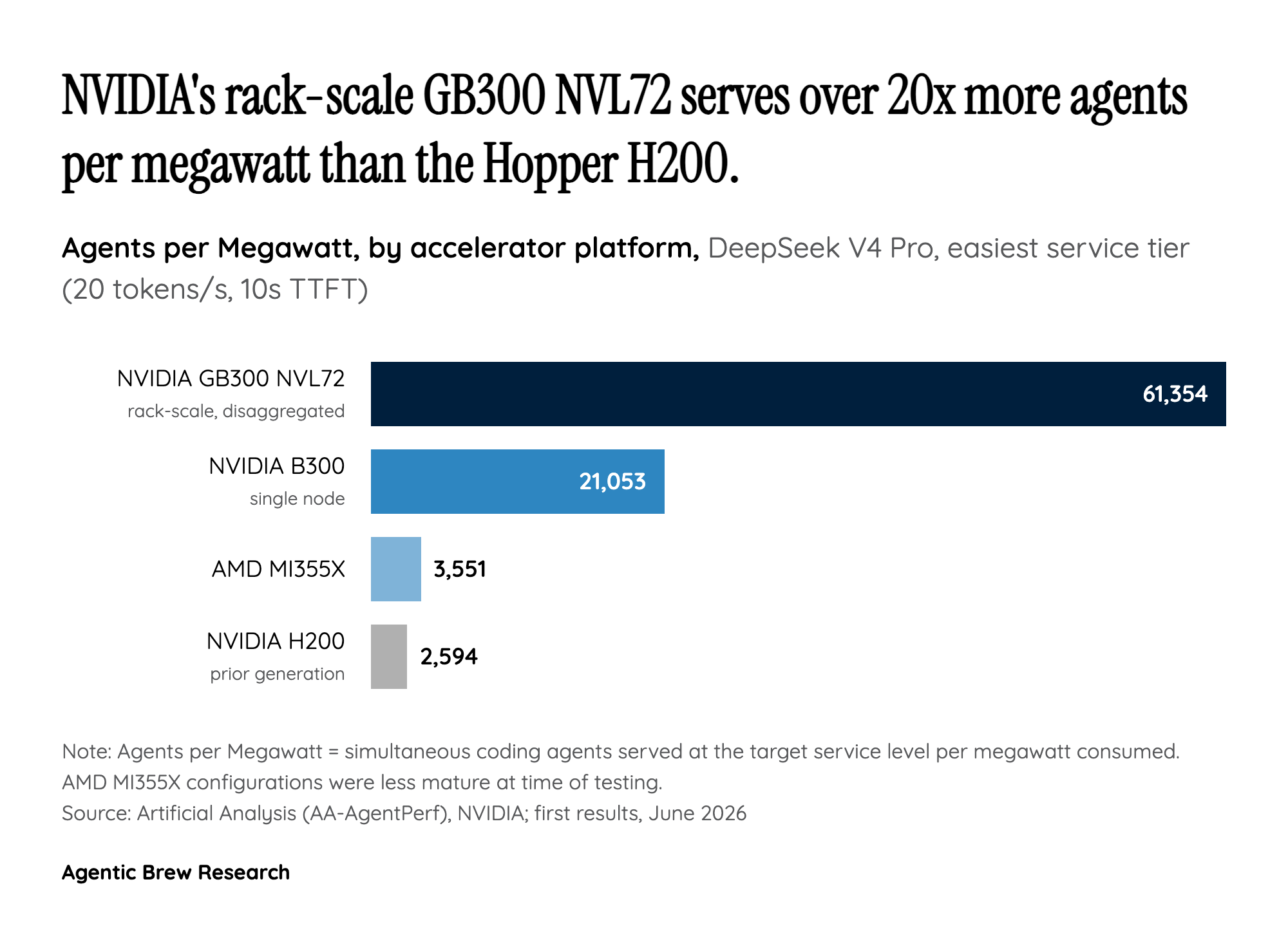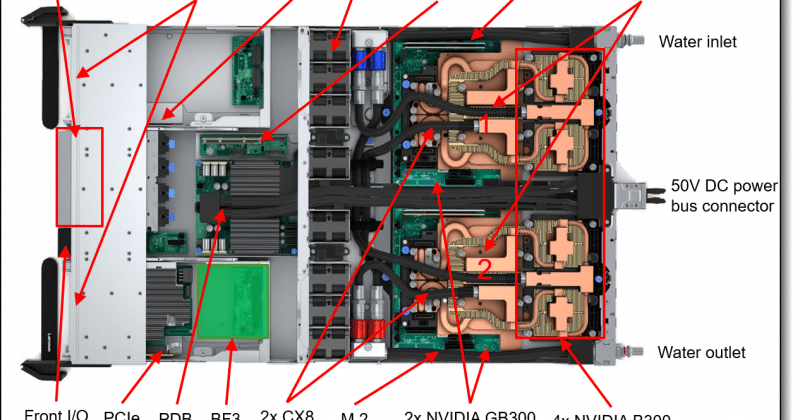
Why 'Agents per Megawatt' is the metric that actually matters
Most inference benchmarks report tokens per second or cost per million tokens. AA-AgentPerf throws those aside for a deliberately different headline number: Agents per Megawatt, the maximum number of concurrent agents an accelerator platform can serve for each megawatt of power it draws [1]. The reasoning is that AI data centers are now bottlenecked by power availability, not rack space or capital, so the right question for a buyer is no longer 'how fast' but 'how many agents can I run inside my power envelope.' What makes the benchmark credible is the workload underneath it: rather than synthetic single-turn prompts, it replays real coding-agent trajectories of up to 200 turns with sequence lengths beyond 100K tokens across 12+ programming languages, scored against multiple service-level tiers [1]. Crucially, it is the first inference benchmark to allow the production optimizations labs actually run, KV cache reuse (reusing already-computed attention state instead of recomputing it), speculative decoding (a small draft model proposing tokens a large model verifies in bulk), and disaggregated prefill/decode (splitting the prompt-ingestion and token-generation phases onto different hardware) [1]. That makes the results a measure of deployable efficiency, not lab-bench throughput.