
Why this cut is permanent: Ascend 950 supply meets long-context engineering
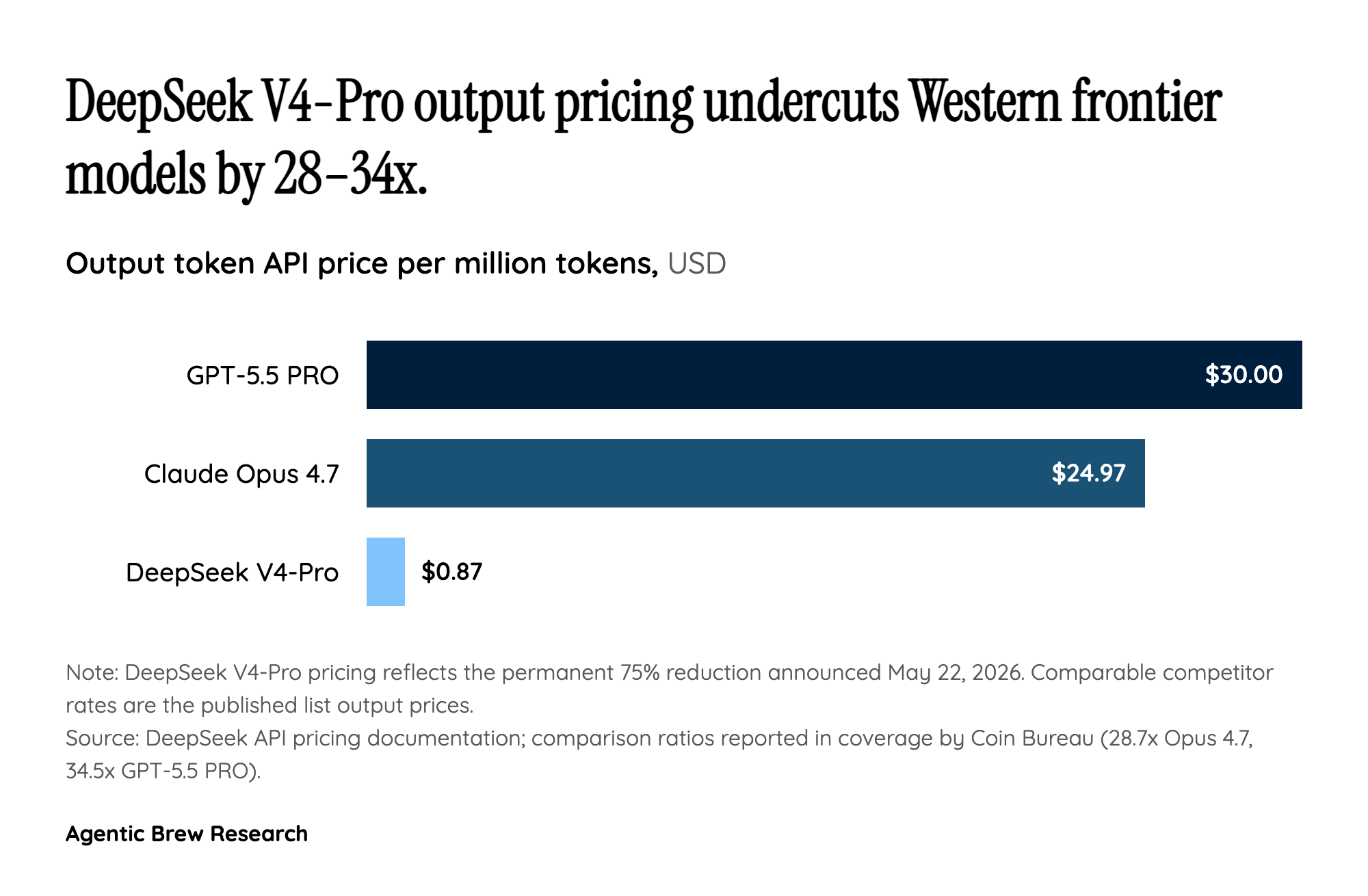
The 75% reduction is not a promo extended one more cycle — it is a permanent reset of the list price, made possible by two things landing at once. First, Huawei's Ascend 950 ramp. Mass production of the 950PR began in April, with Huawei targeting roughly 750,000 units shipped in 2026 and full-scale volume in H2 [1]. ByteDance, Tencent and Alibaba placed new orders within days of the V4 launch, confirming that DeepSeek is not the only customer absorbing the supply [1]. Second, V4-Pro was engineered around the dominant cost driver of agentic workloads: long-context inference. Greyhound Research's Sanchit Vir Gogia notes the architecture was engineered to cut the cost of long-context inference [2], and the cache-hit input rate of $0.003625/M tokens — 1/120th of the cache-miss rate — points to aggressive KV-cache reuse on the 1M-context window DeepSeek shipped a month earlier [3]. The April 26 cut of cache-hit pricing across all DeepSeek models to 1/10 of launch was the foreshadowing [4]; the permanent V4-Pro cut is the structural follow-through. The point: this is a hardware-plus-architecture price floor, not a marketing flag.


