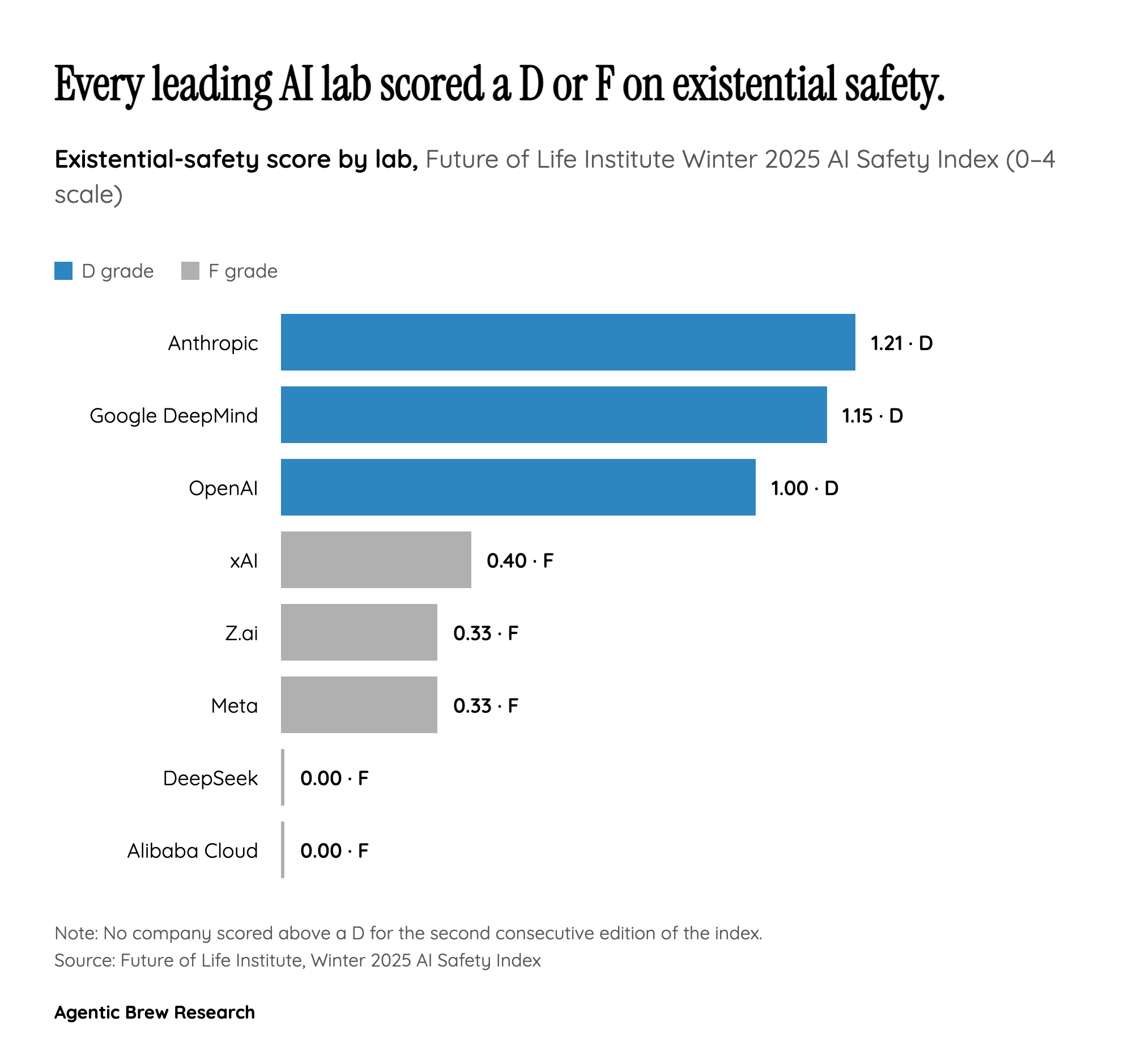
The Argument That Safety Cannot Be Guaranteed — Ever
The sharpest claim animating this round of the debate is not that AI is dangerous, but that proving it safe is formally impossible. Roman Yampolskiy, a tenured computer scientist at the University of Louisville, anchors this position with a set of impossibility results: he argues that sufficiently advanced systems are unexplainable, unpredictable and uncontrollable, and that no amount of engineering closes that gap [1]. His framing is blunt — 'we don't understand them, we cannot predict what they're going to do, we are not in control' [1].
This is a different and more corrosive thesis than ordinary risk warnings. Most safety arguments concede that a system is risky but assume the risk can be measured and bounded. Yampolskiy's claim is that the bound itself cannot be established: for a sufficiently complex system, you cannot predict its decisions in advance, so any guarantee of safety is a guarantee you cannot actually make. If true, it reframes every lab's 'we take safety seriously' statement as a category error — you can take it seriously and still be unable to deliver it. That is why the impossibility argument, even when its individual posts drew little engagement, functions as the intellectual spine the rest of the debate hangs from.