The Headline Says Mythos. The Footnote Says the Harness Won.
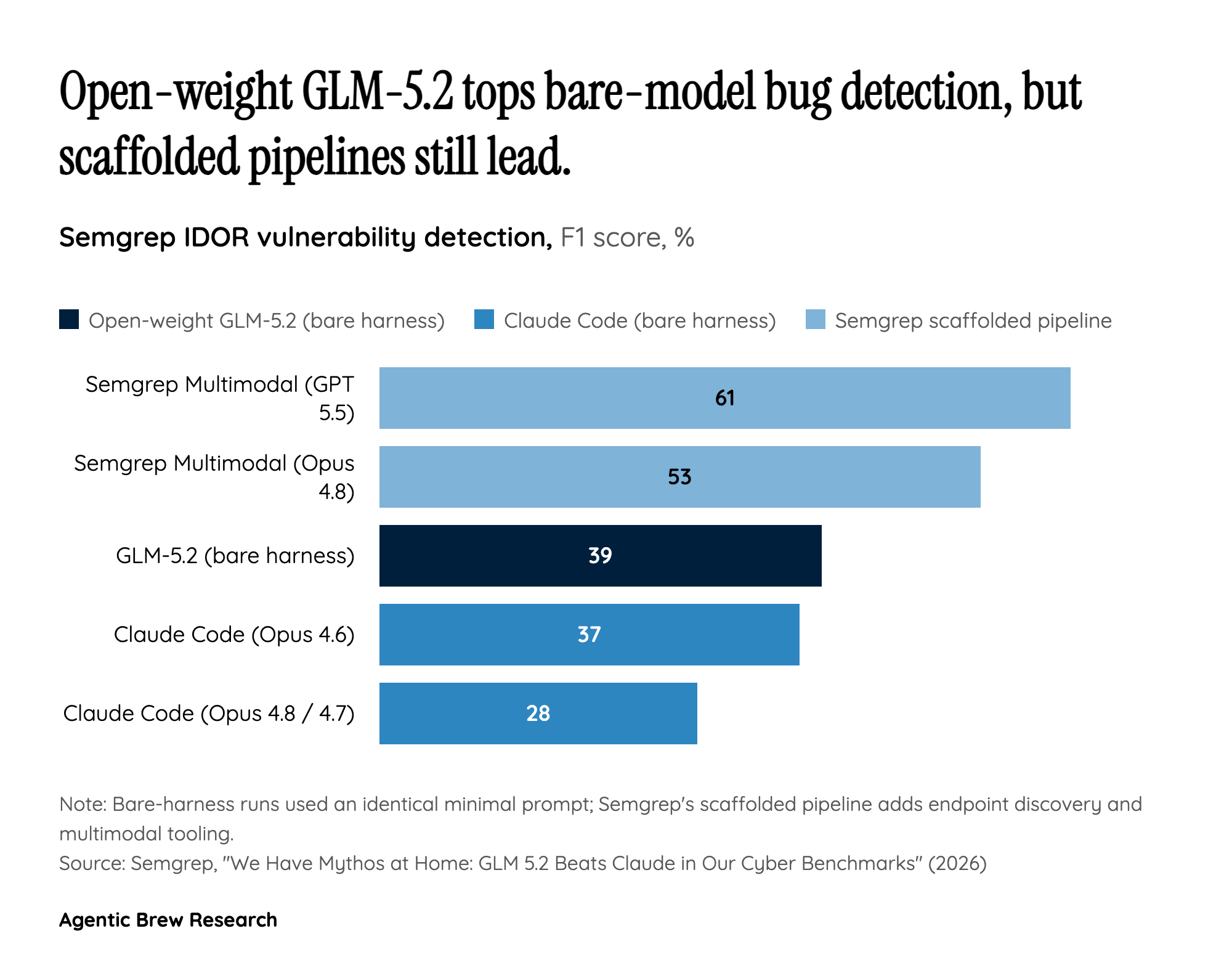
The viral framing - a Chinese open-weight model 'matched Claude Mythos in cybersecurity' - compresses a much narrower result into a geopolitical headline. The benchmark that everyone is citing comes from Semgrep, and Semgrep was unusually careful to fence off what it actually showed: GLM-5.2 beat Claude Code on exactly one vulnerability class, IDOR (insecure direct object reference), when both models were handed the same minimal prompt and the same bare harness [1].
The nuance that gets lost is that the model is only one ingredient. Semgrep's own production pipeline - the same underlying frontier models wrapped in endpoint discovery and multimodal scaffolding - scored far higher than any bare-model run, with the GPT 5.5 configuration at 61% F1 and the Opus 4.8 configuration at 53% [1]. In other words, the scaffolding around a model contributed more lift than the gap between GLM-5.2 and Claude Code. Semgrep states plainly that 'this is not an apples-to-apples comparison of raw model ability' [1]. The honest read is not 'China matched Mythos' but 'a cheap open model is now good enough that the harness, not the model, is the real differentiator in agentic security work.'