The architecture bet: hybrid Mamba-Transformer at 550B, scaled for million-token agent loops
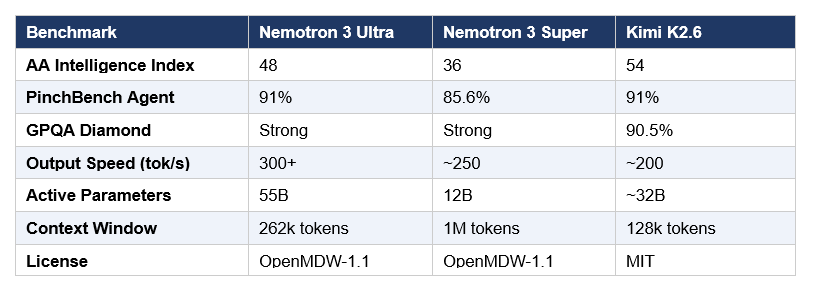
Nemotron 3 Ultra is not a vanilla dense or MoE transformer. It is a hybrid Mamba-Transformer Mixture-of-Experts: 550B total parameters with 55B active per token, 108 layers, an 8,192 model dimension, 512 experts per layer, and top-22 routed per token [2]. The Mamba state-space component is what makes the 1M-token context window economical — attention's quadratic cost is replaced by linear-time selective scans on long ranges, while a smaller proportion of transformer blocks preserves the precise recall that long-horizon agents need.
That design choice is downstream of the workload. Long-running agents accumulate hundreds of tool calls, scratchpads, and retrieved documents per task; a 1M-token window means the agent can carry that working memory inside the model rather than offloading it to a vector store. The benchmarks NVIDIA highlights — RULER@1M of 94.7/95% needle-in-haystack recall and SWE-Bench Verified of 71.9 — are the ones a long-context agent actually fails on when its architecture is wrong [1][2]. In other words, NVIDIA is not chasing a raw intelligence score; it is chasing the intelligence-at-long-context curve.