The breakthrough isn't the CPU — it's stitching 13.8 million cores together
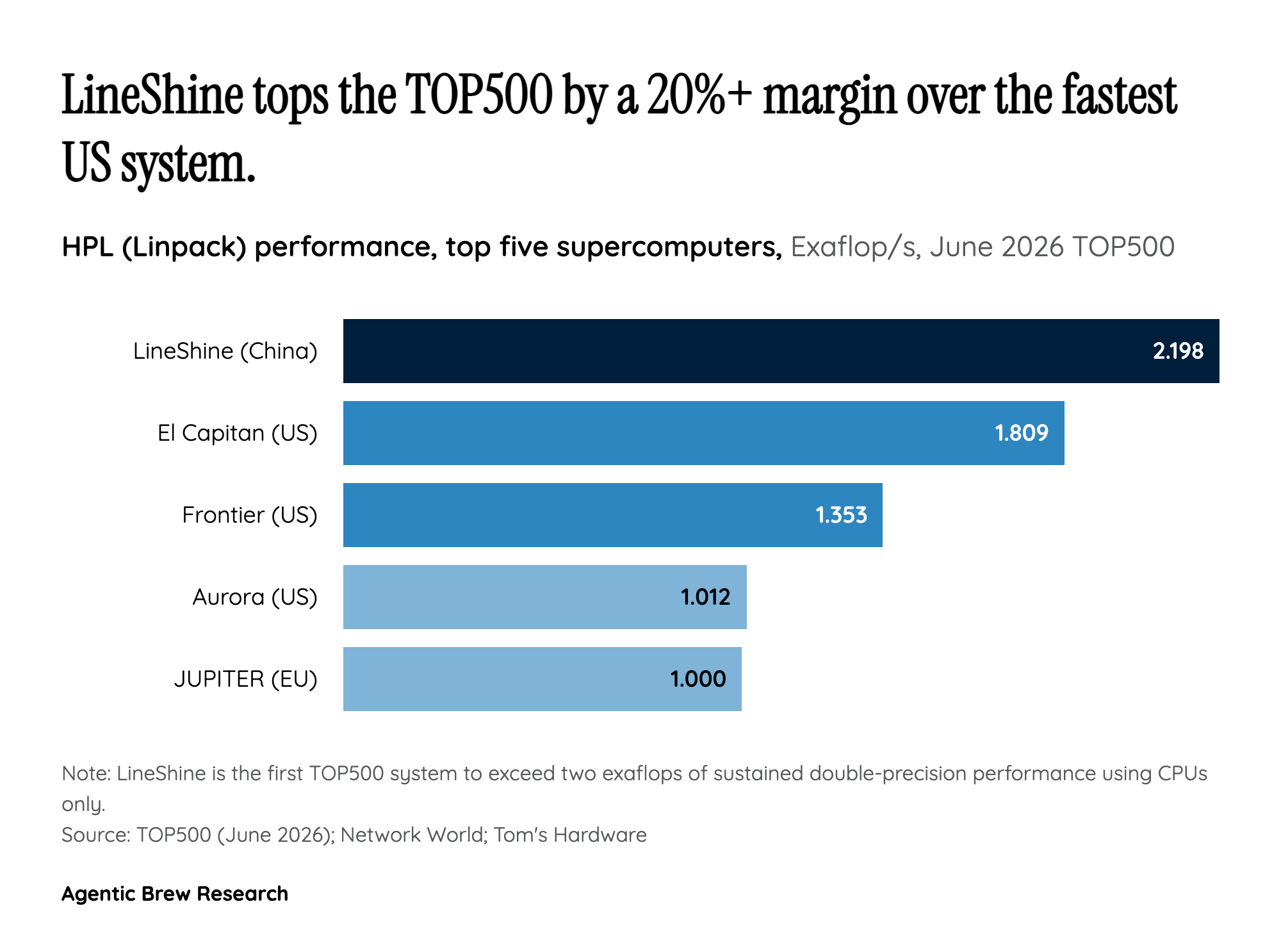
LineShine's headline is that it hit exascale with zero GPUs, but the harder engineering problem it solved is the network. The machine is built from 304-core LX2 processors on China's LingKun platform, totaling roughly 13.79 million cores, and lashes them together with a proprietary LingQi interconnect on the Kylin OS [4]. Reaching 2.198 exaflops on Linpack — about 80% of its 2.736 EF/s theoretical peak — means the interconnect is keeping that ocean of cores fed efficiently enough to sustain double-precision math at scale [1]. Technical readers parsing the design landed on the same conclusion: the standout is the LingQi fabric and the converged HPC-plus-AI topology, not the cores themselves, which several observers note resemble Japan's Fugaku (Fujitsu's A64FX many-core, big-vector approach) far more than they resemble Google TPUs. CPUs with wide vector and matrix extensions, not accelerators, are doing the heavy lifting — and the network is what turns millions of them into one coherent machine.