Open weights are now a coding-benchmark point or two behind the closed frontier
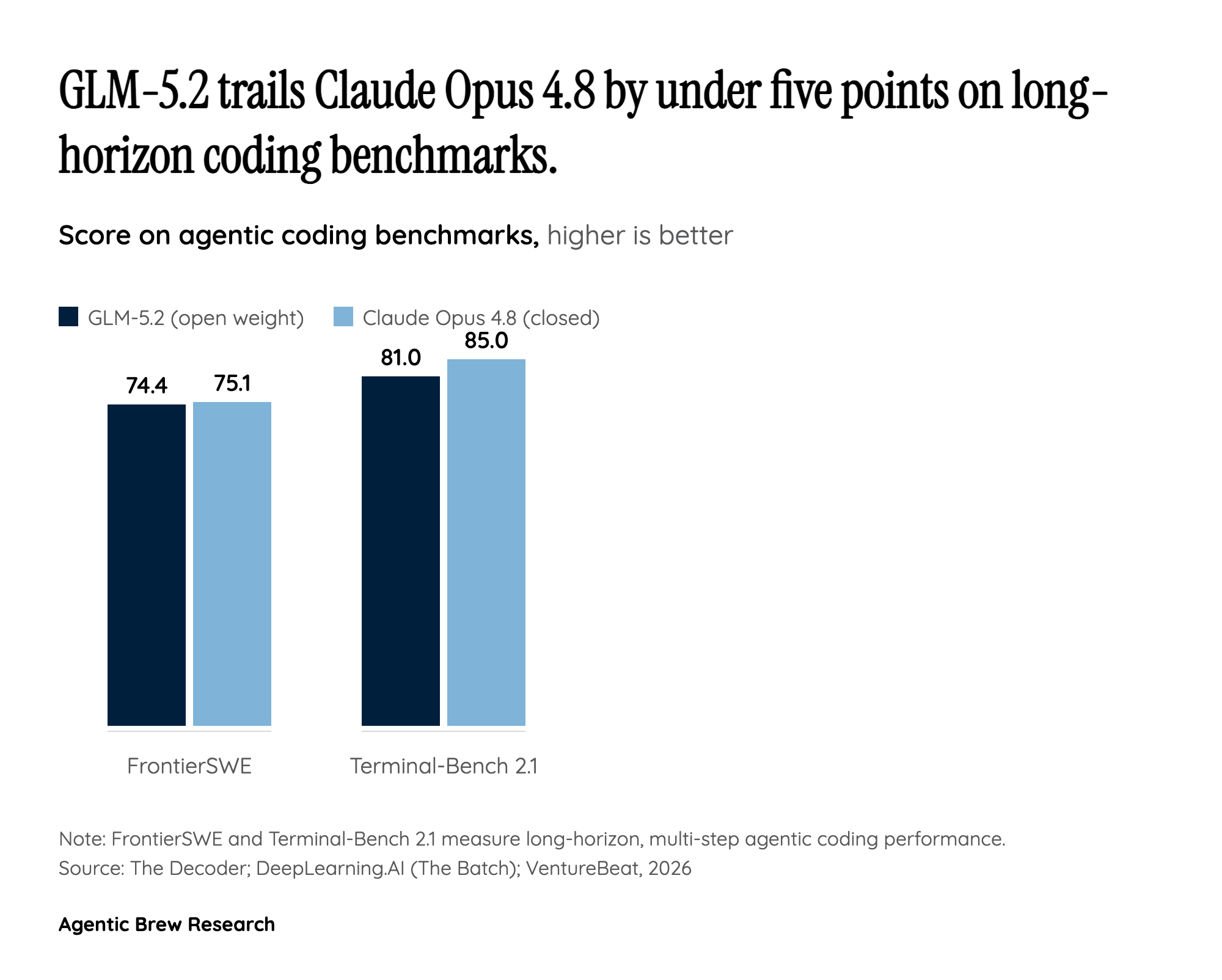
The headline isn't that another open model shipped, it's how little daylight is left at the top. On Terminal-Bench 2.1, GLM-5.2 scores 81.0, a large jump from GLM-5.1's 63.5 and within striking distance of Claude Opus 4.8's 85.0 [2][3]. On FrontierSWE it posts 74.4% against GPT-5.5's 72.6% and Opus 4.8's 75.1%, and on SWE-bench Pro it edges both closed rivals at 62.1 versus 58.6 and 58.4 [2][5]. DeepLearning.AI's The Batch summarizes the result cleanly: GLM-5.2 ranks second only to Claude Opus 4.8 across three multi-hour coding benchmarks, and substantially ahead of its own predecessor [3]. It also tops the Artificial Analysis Intelligence Index v4.1 at 51, well above the next open models MiniMax-M3 and DeepSeek V4 Pro, which max out around 44 [1][2].
The caveat from The Decoder is that the gap is narrowest on coding marathons specifically; on broader reasoning it still trails Opus 4.8 and Gemini 3.1 Pro [2]. Developer reception tracked this story closely: hands-on reviewers on YouTube ran their own coding gauntlets and arrived at numbers a few points below Opus rather than at parity, and community testers probed the 'beats GPT-5.5' claim directly rather than taking it on faith. The shape of the conversation was less 'is it the best' and more 'how close, and on which tasks' — a question that would have been unthinkable for an open model a year ago.