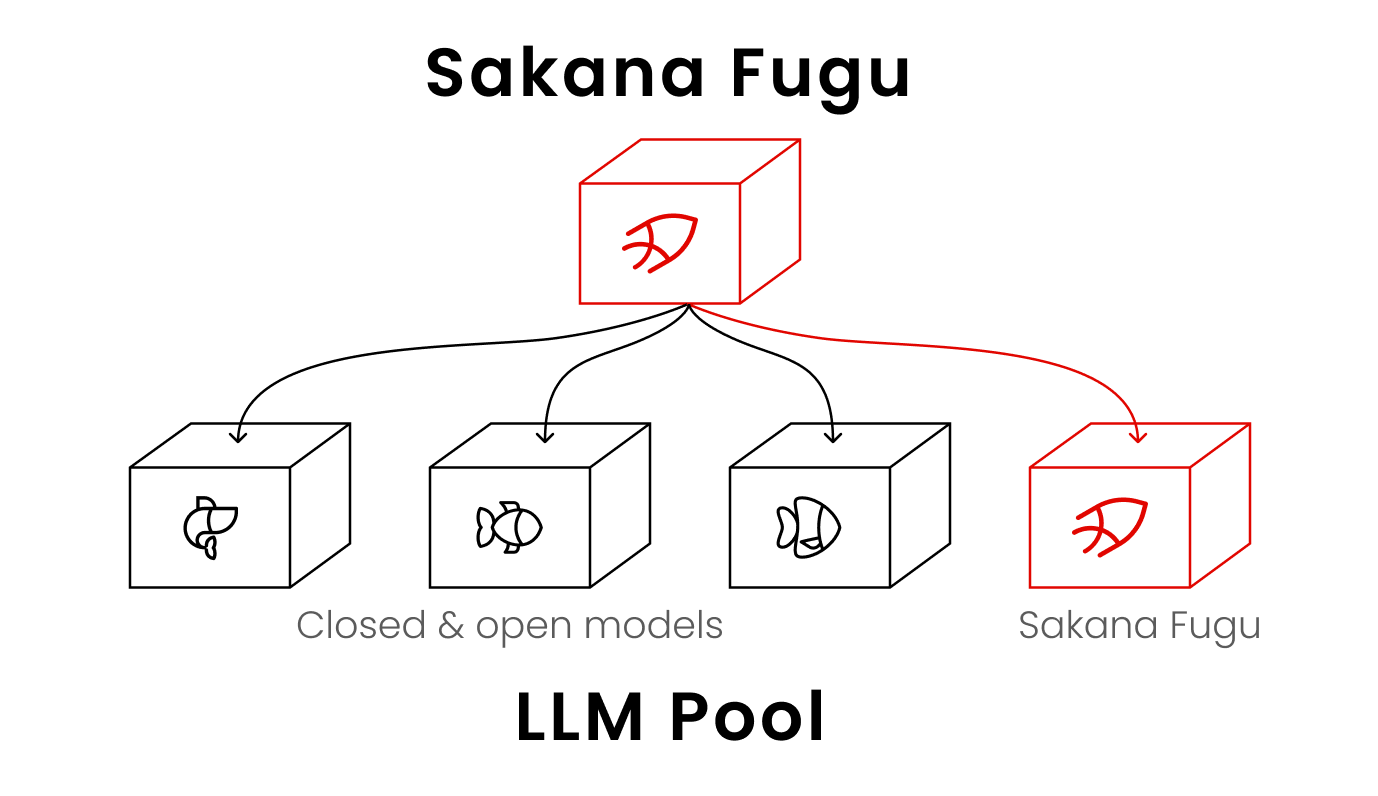
An LLM That Hires Other LLMs
Fugu inverts the dominant scaling playbook. Rather than train one ever-larger model, Sakana built a comparatively small router LLM that calls other LLMs, including instances of itself recursively, and coordinates them behind a single OpenAI-compatible endpoint [1]. When a request arrives, Fugu doesn't necessarily answer it directly; it decides whether to solve the task itself or assemble a team of expert models, then delegates, verifies, and synthesizes a single reply. The orchestration leans on three adaptive roles: a Thinker that plans, a Worker that executes coding and applied tasks, and a Verifier that checks outputs for errors, hallucinations, and requirement compliance [1].
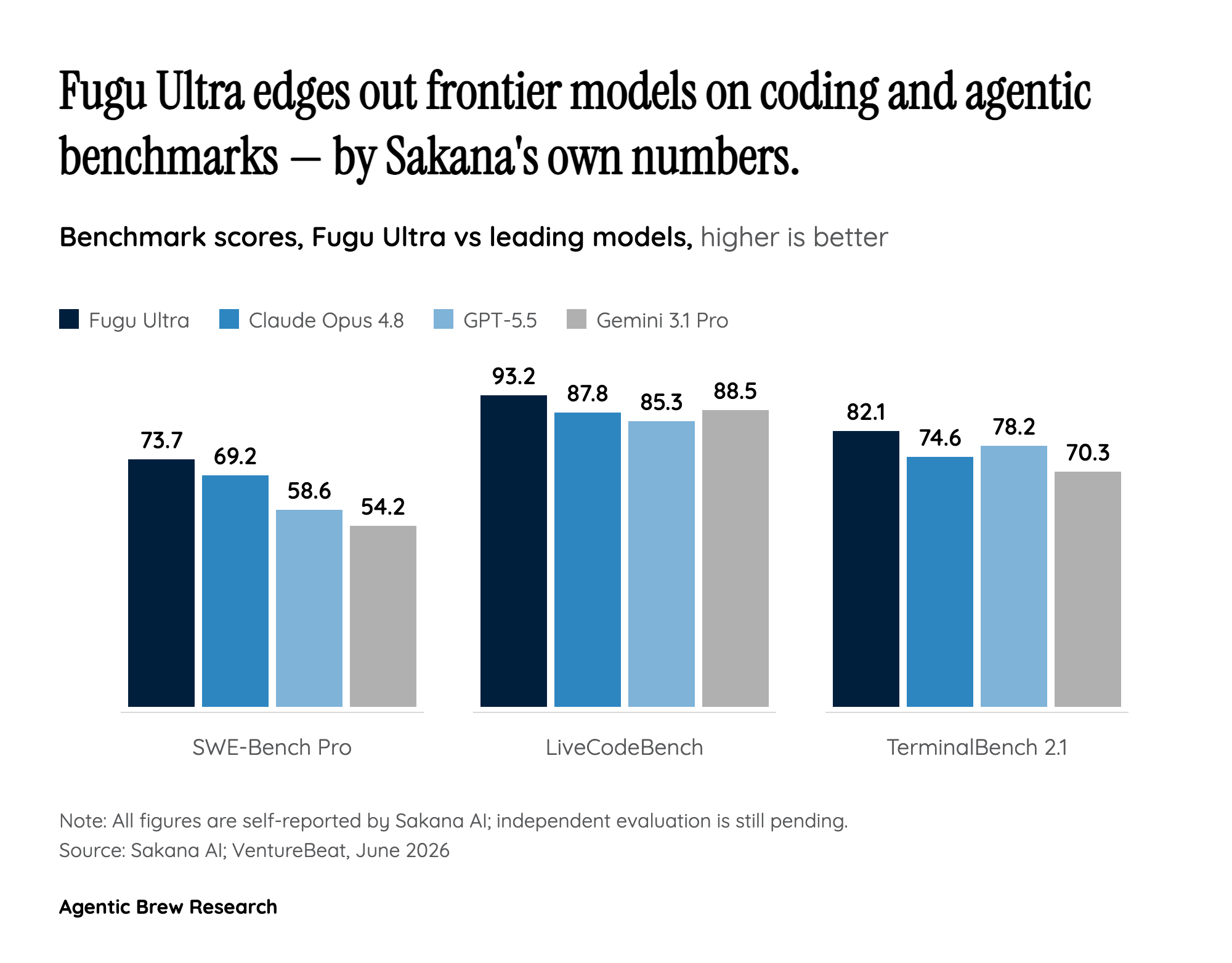
MarkTechPost describes the result as an orchestration model that routes tasks across a swappable pool of frontier LLMs [6]. Two variants ship through one API: a low-latency base Fugu for everyday work and Fugu Ultra, which marshals a deeper pool of agents for hard, multi-step problems like research, cybersecurity, and patent search. The architecture is grounded in two ICLR 2026 papers, TRINITY and Conductor [1]. The practical upshot for a developer is that the complexity of a multi-agent system never reaches their code; it looks, and bills, like a single model.