GLM 5.2 By The Numbers: How Close Is It Really?
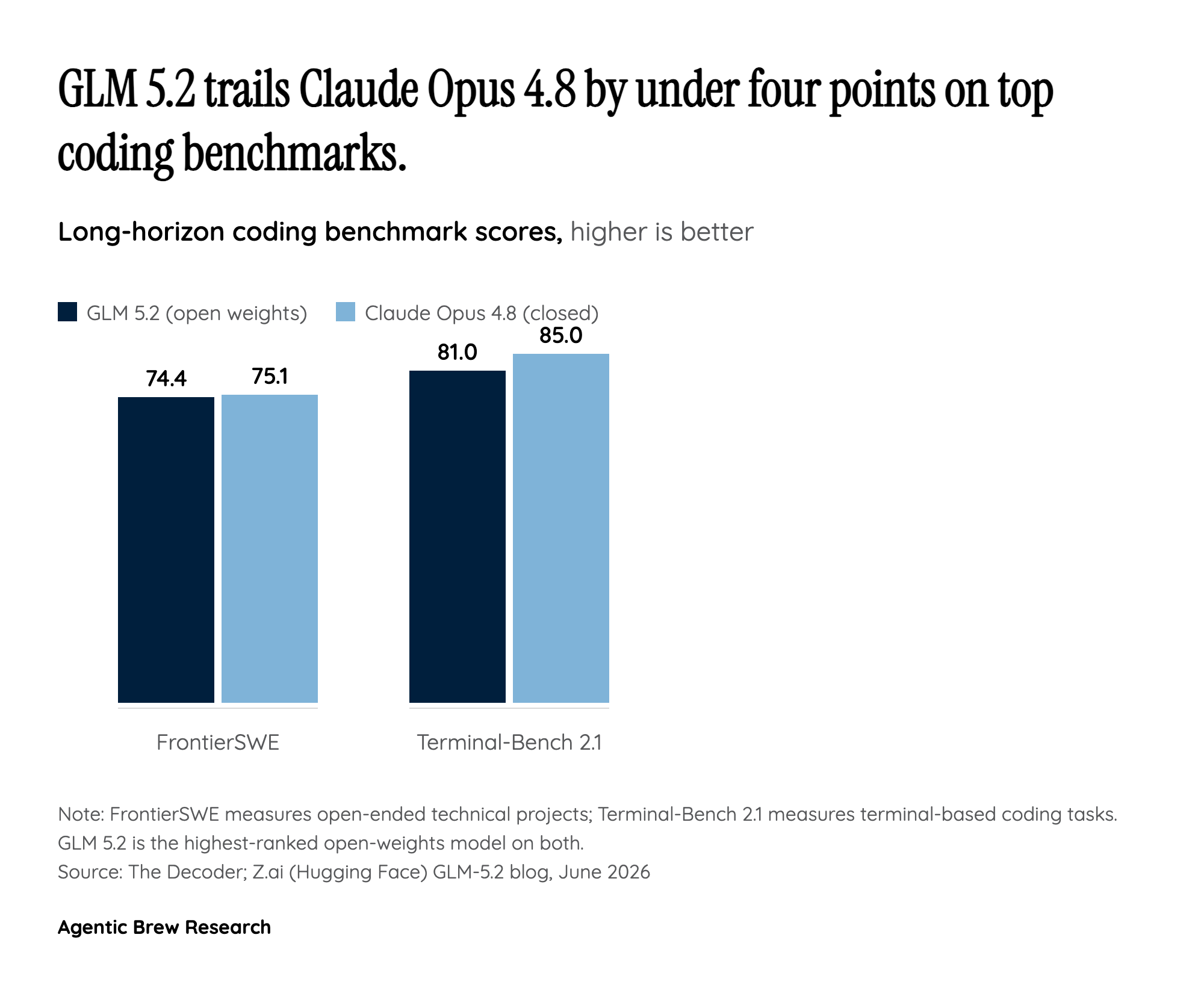
On the headline coding benchmarks, GLM-5.2 has genuinely closed the gap with closed frontier labs. On FrontierSWE it scores 74.4, trailing Anthropic's Claude Opus 4.8 (75.1) by about a single point and edging out GPT-5.5 (72.6) [4][5]. It posts 62.1 on SWE-bench Pro, up sharply from GLM-5.1's 58.4 and ahead of GPT-5.5's roughly 58.6 [1][4]. Terminal-Bench 2.1 climbed to 81.0 from 63.5, though Opus 4.8 still leads at 85.0 [1][4]. It places second overall on Code Arena (1,595 points) and first among globally available models, and tops the open field on Artificial Analysis's Intelligence Index v4.1 at 51, ahead of MiniMax-M3, DeepSeek V4 Pro, and Kimi K2.6 [5][6].
But the gap reopens on the hardest, longest tasks: GLM-5.2 reportedly reaches only about half of Opus 4.8's SWE-Marathon score and lags on Humanity's Last Exam [4]. The honest read is a model that has caught the frontier on standard coding benchmarks but still trails it on the most demanding long-horizon work.