Why AI Made Memory the New Bottleneck - and Why HBM Prints Money
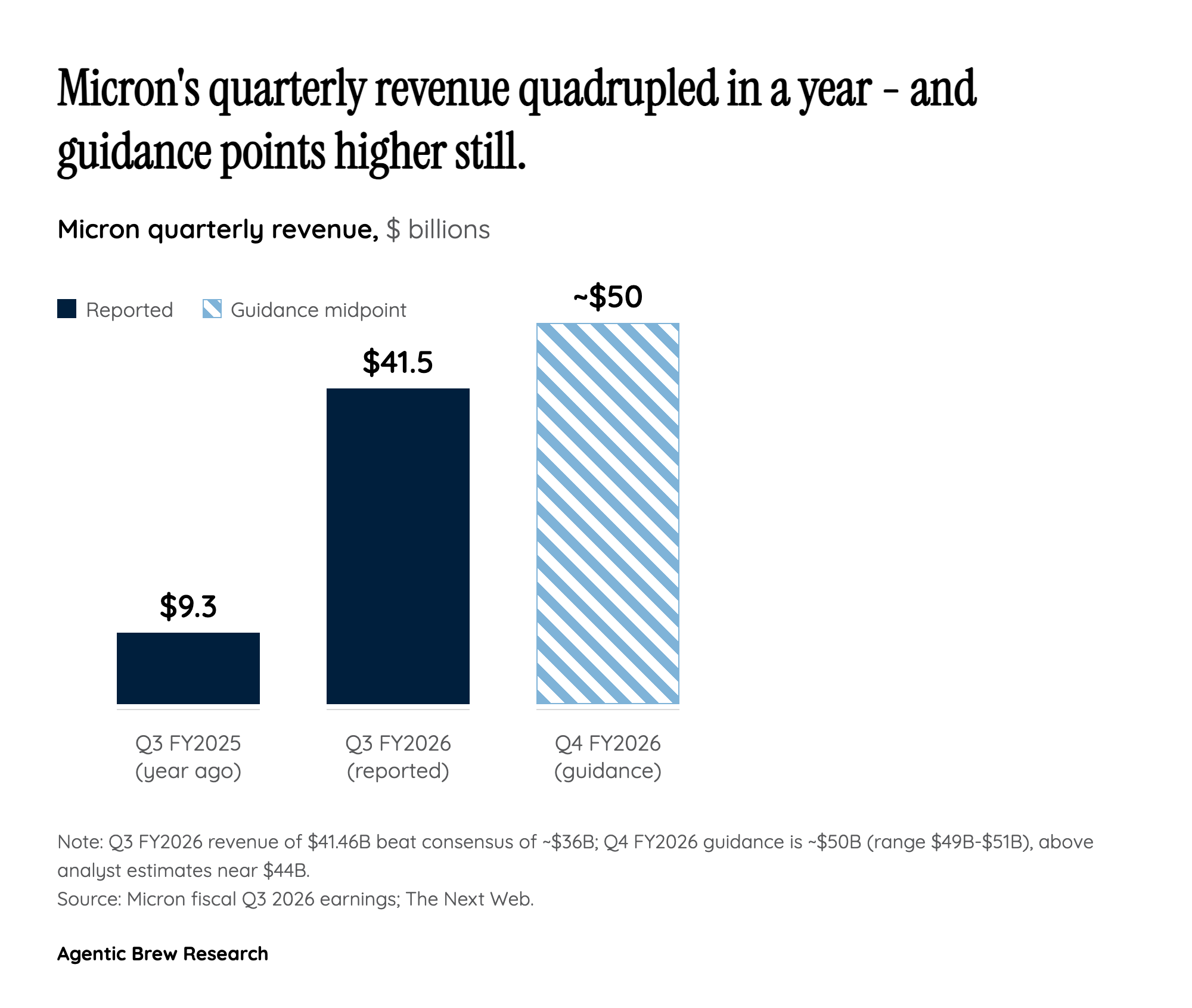
For a decade the AI story was about compute: who had the fastest GPUs. Micron's quarter is the moment the bottleneck visibly moved. A single AI server needs orders of magnitude more memory than a laptop, and every advanced AI accelerator ships with stacks of high-bandwidth memory (HBM) sitting right next to the chip [1]. HBM is not commodity DRAM - it is DRAM dies stacked vertically and wired to the processor at enormous bandwidth, which is exactly what feeds a GPU fast enough to keep its cores busy. Micron's newest part, HBM4 36GB 12H, runs over 2.8 TB/s of bandwidth, 2.3 times that of the prior HBM3E generation, and is designed specifically for NVIDIA's Vera Rubin systems [7].
The economics are what turned a cyclical chipmaker into a Wall Street darling. HBM carries far richer margins than ordinary memory, and the shift in product mix drove Micron's gross margin above 81 percent, up from 69 percent the prior quarter [3]. HBM4 revenue already crossed $1 billion in a single quarter and is ramping roughly twice as fast as HBM3E did [3]. The deeper signal is in the bill of materials: as accelerators advance, the memory cost is rising far faster than the GPU silicon itself, which is why a memory supplier - not just the chip designer - is suddenly capturing a growing share of every AI system's value. That is the mechanism behind the headline numbers, and it is why analysts are willing to entertain the comparison to Nvidia at all [4].