Orchestration Is the Model Now
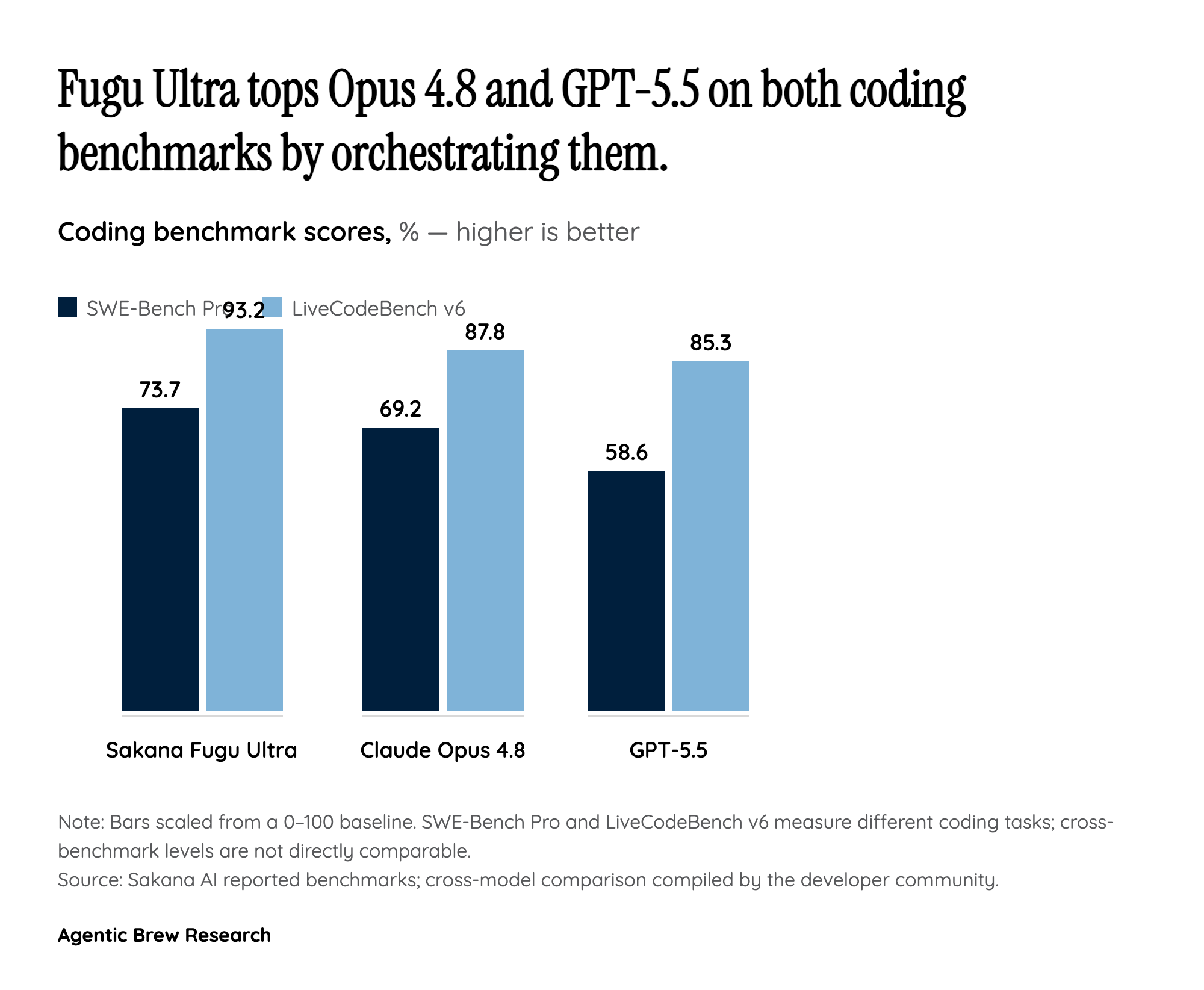
The most consequential move Sakana made is not a benchmark score but an inversion of where the product lives. Instead of training a bigger frontier model, Fugu is itself a language model trained to command other LLMs: it selects models, delegates subtasks, verifies their work, and synthesizes one answer, so that from the outside you call a single model [1]. The intelligence is grounded in two Sakana papers accepted at ICLR 2026 — TRINITY, an evolved lightweight coordinator that assigns Thinker, Worker, and Verifier roles across turns, and The Conductor, which uses reinforcement learning to discover natural-language coordination strategies [1]. As Sakana frames it, Fugu learns how to coordinate, deciding when to delegate and how agents should communicate, rather than following a hand-written router script. A hands-on tester who routed a real task through it watched Fugu break the work into subtasks dispatched to the best available back-end model, with high-quality synthesis at the end. The bet underneath is that the orchestration layer, not the underlying model, is becoming the differentiated commercial offering [2].