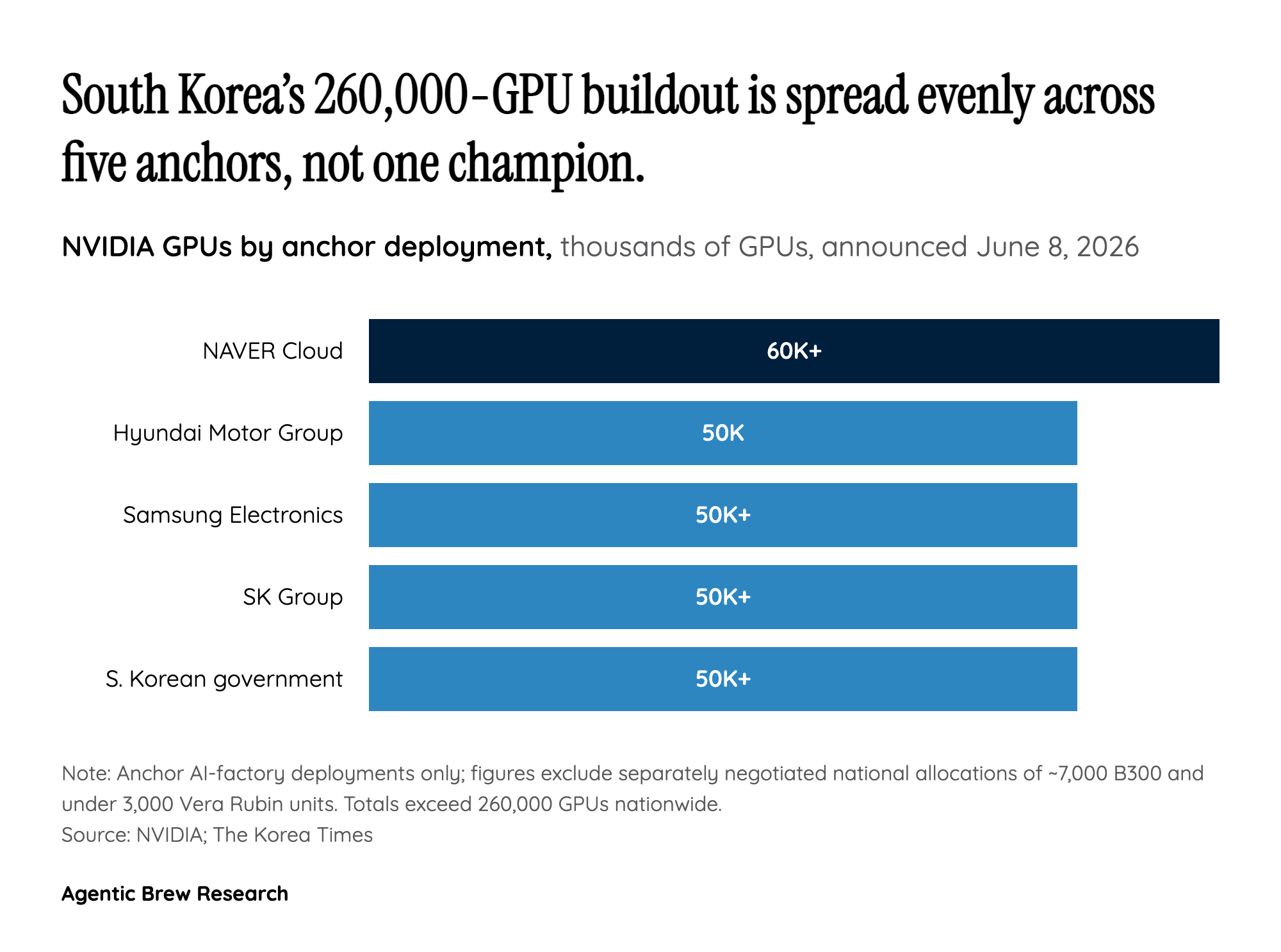
Memory stopped being a commodity the moment it had to be co-designed
The most consequential line in NVIDIA's Korea announcement is not a GPU count but a sentence about scheduling. Jensen Huang said NVIDIA and SK hynix are "co-designing our road maps together so that Nvidia's architecture and SK hynix's memory technology can advance together" [4]. That is a quiet admission that high-bandwidth memory — HBM, the stacked DRAM that sits next to an accelerator and feeds it data — can no longer be sourced after a chip is finished. A Vera Rubin-class system's bandwidth, power envelope and thermal behavior are determined years before silicon ships, which means the memory has to be specified in lockstep with the compute, not bolted on at the end. By signing a multi-year deal spanning Vera Rubin supercomputers, Vera CPUs, RTX Spark PCs and Jetson Thor robotics, NVIDIA is effectively reserving a seat for SK hynix at its own design table [1].
The market read this correctly as a structural shift, not a one-off order. NH Investment & Securities' Ryu Young-ho noted the partnership "reinforced the view that memory chips were evolving from a commodity product into a more customer-specific business" [5]. SK Group's Chey Tae-won extended the logic in the other direction: the same partnership has SK hynix "applying AI to how we design and manufacture semiconductors" using NVIDIA's CUDA-X and PhysicsNeMo [1]. So the relationship runs both ways — NVIDIA's roadmap pulls custom memory out of SK hynix, while SK hynix pulls NVIDIA's simulation and physics tooling into its fabs. Commodity DRAM was fungible and interchangeable; co-designed HBM is sticky, and stickiness is exactly what NVIDIA wants when memory is the bottleneck for the entire AI buildout.