
X.com
17395
The AI Layoff Trap
Brett Hemenway Falk, Gerry Tsoukalas
The most upvoted and starred AI research crossing the community today.
Last Brew Time: May 2, 2026, 9:33 AM PT
Brett Hemenway Falk, Gerry Tsoukalas

Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, Mehrdad Farajtabar

Bojie Li

Zhiheng Liu, Weiming Ren, Xiaoke Huang

Sidharth Hariharan, Christopher Birkbeck, Seewoo Lee
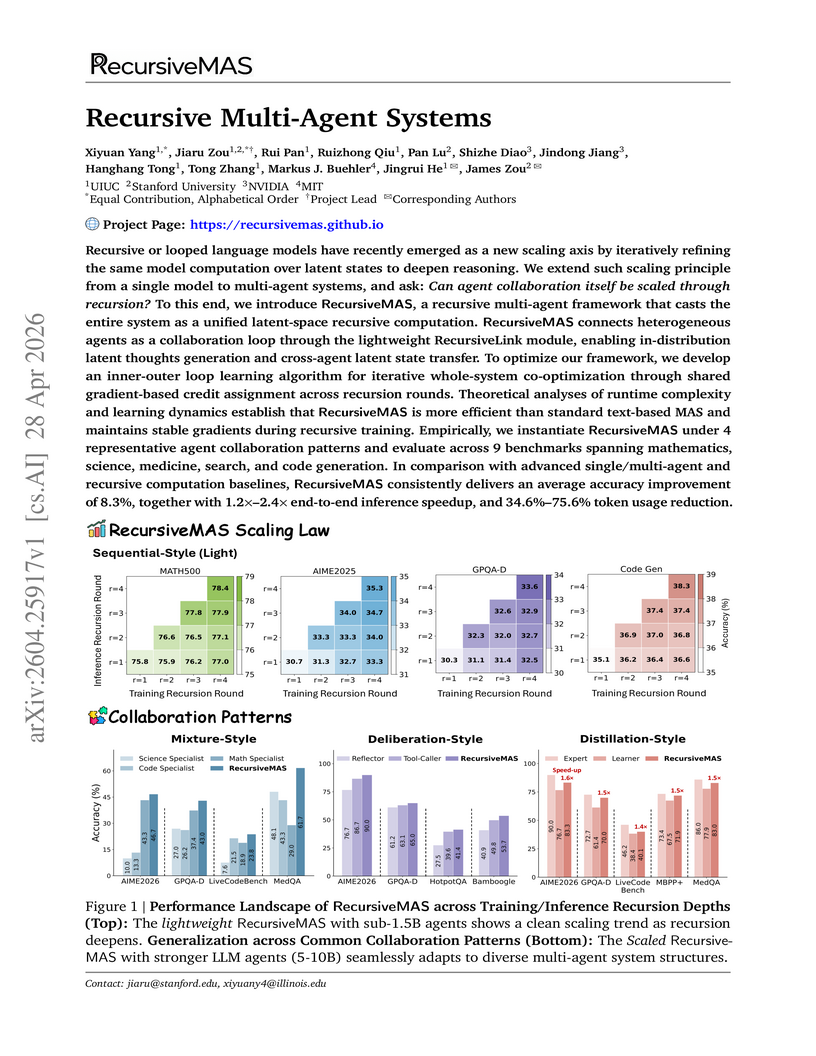
Xiyuan Yang, Jiaru Zou, Rui Pan

Ruijie Lu, Yiyang Ma, Xiaokang Chen

Jiahang Lin, Shichun Liu, Chengjun Pan

NVIDIA, Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le
NVIDIA

Jinbiao Wei, Kangqi Ni, Yilun Zhao, Guo Gan, Arman Cohan

Xinxin Liu, Ming Li, Zonglin Lyu, Yuzhang Shang, Chen Chen

Ming Li, Jie Wu, Justin Cui, Xiaojie Li, Rui Wang

Yanting Wang, Chenlong Yin, Ying Chen, Jinyuan Jia

Emaan Bilal Khan, Amy Winecoff, Miranda Bogen, Dylan Hadfield-Menell
System online.