
X.com
6269
Hiding an Ear in Plain Sight: On the Practicality and Implications of Acoustic Eavesdropping with Telecom Fiber Optic Cables
Youqian Zhang, Zheng Fang, Huan Wu +3 more
The most upvoted and starred AI research crossing the community today.
Last Updated: Apr 8, 2026, 12:03 PM PT
Youqian Zhang, Zheng Fang, Huan Wu +3 more

Kartik Chandra, Max Kleiman-Weiner, Jonathan Ragan-Kelley +1 more
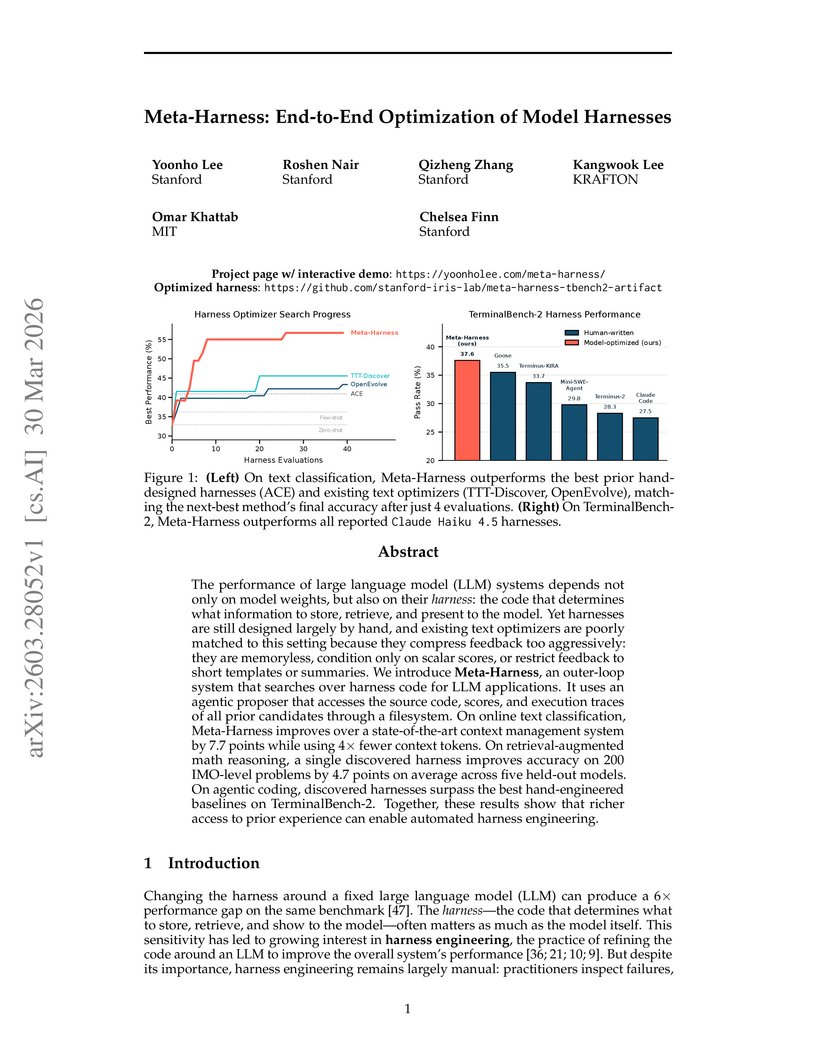
Yoonho Lee, Roshen Nair, Qizheng Zhang
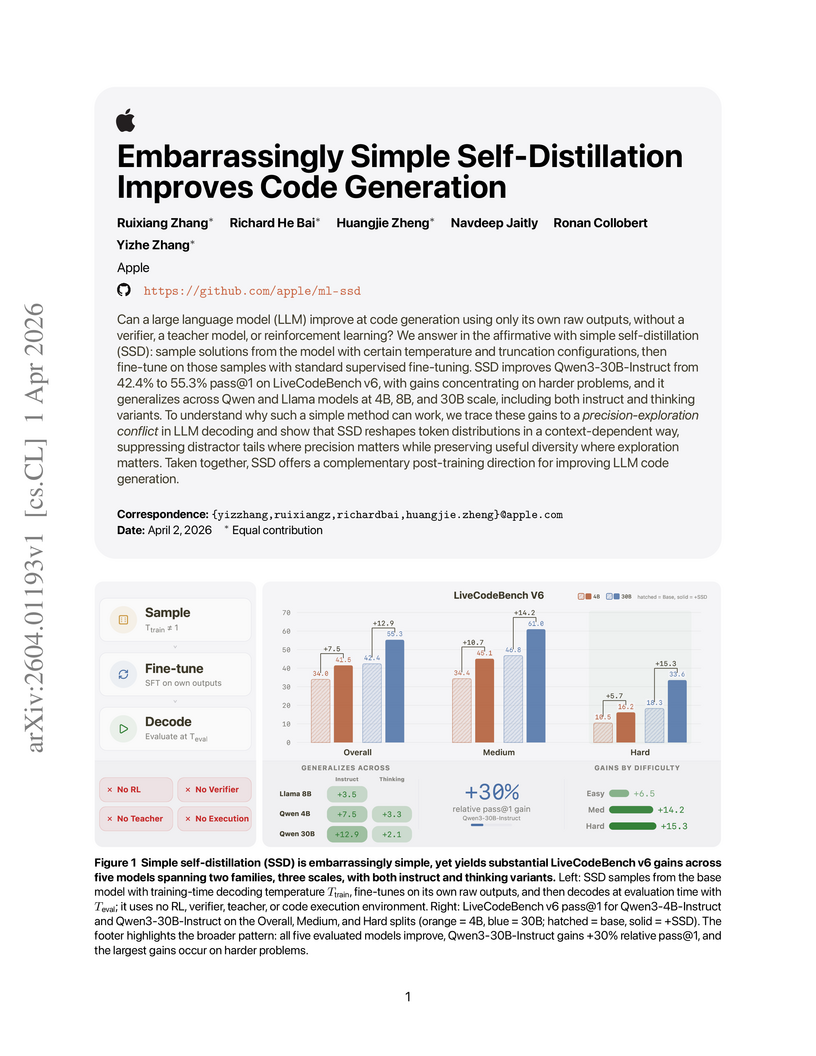
Ruixiang Zhang, Richard He Bai, Huangjie Zheng

Zhengxi Lu, Zhengxi Lu, Zhiyuan Yao +1 more
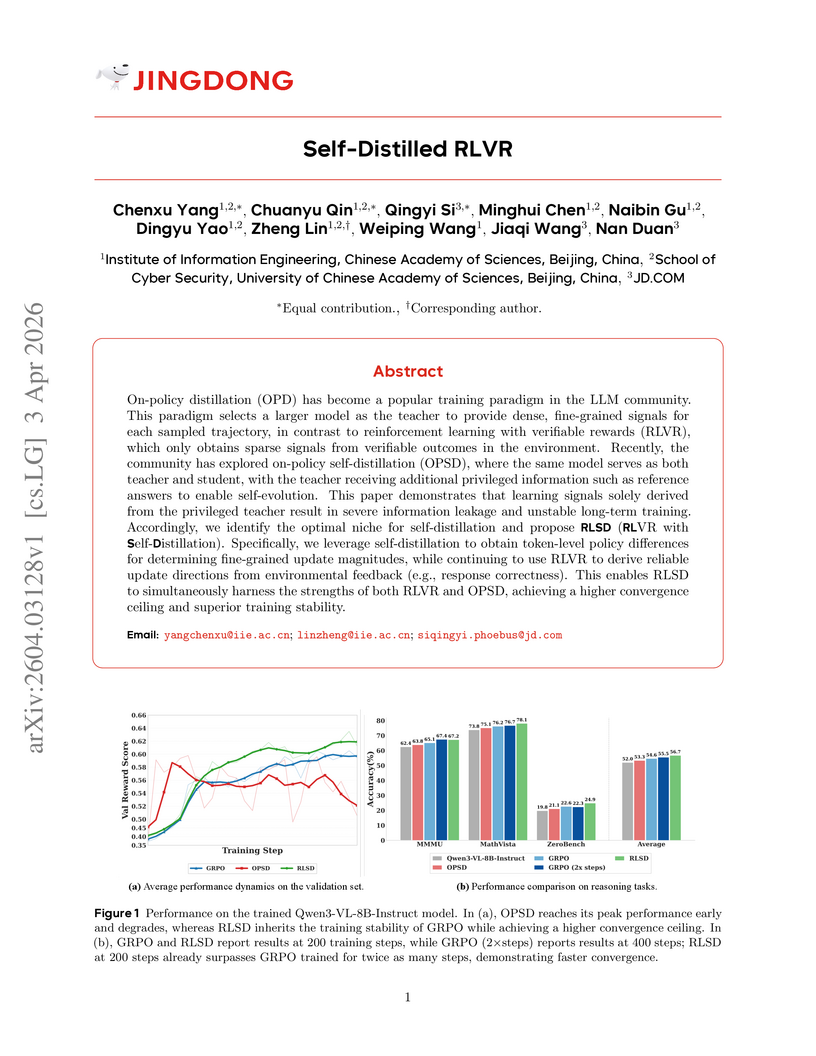
Chenxu Yang, Chuanyu Qin, Qingyi Si
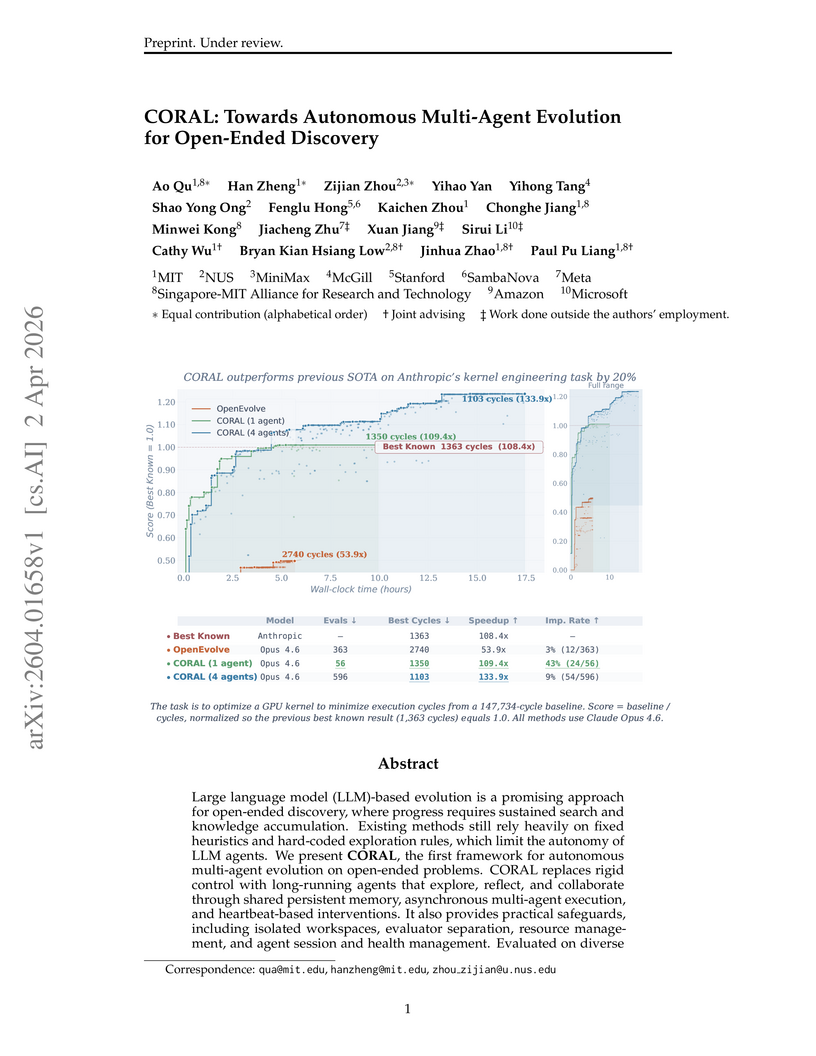
Ao Qu, Ao Qu, Han Zheng +1 more

Gabriel Sarch, Linrong Cai, Qunzhong Wang

Jarrid Rector-Brooks, Théophile Lambert, Marta Skreta +2 more

Xiangyi Li, Kyoung Whan Choe, Yimin Liu +2 more

Ádám Kovács

TianZe Zhang, Sirui Sun, Yuhang Xie +2 more

Shuibai Zhang, Caspian Zhuang, Chihan Cui +2 more

Siddharth Jain, Venkat Narayan Vedam
System online.