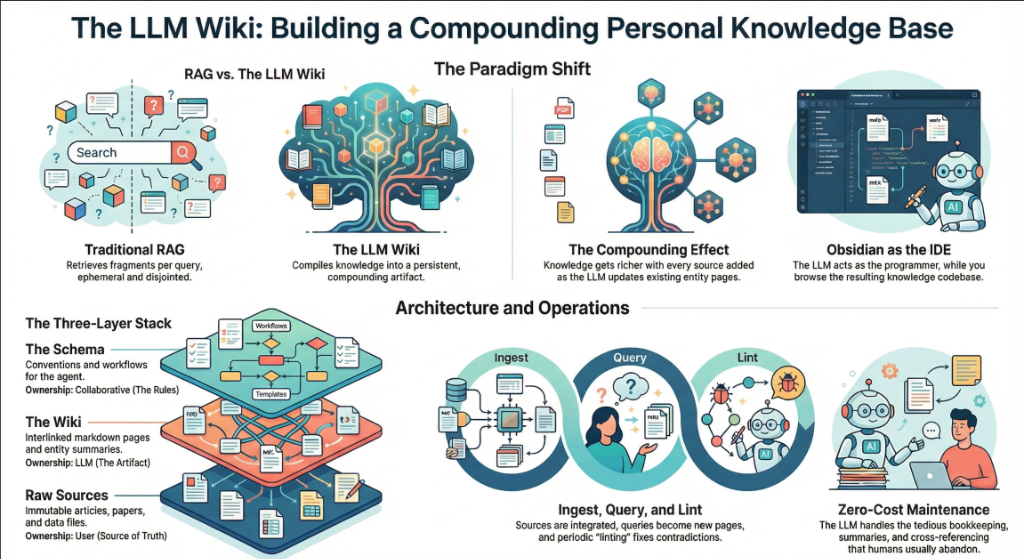
From RAG to Compilation: Why Karpathy Thinks Vector Databases Are Overkill
The dominant paradigm for giving LLMs access to personal or enterprise knowledge has been Retrieval-Augmented Generation — embedding documents into vector databases and retrieving relevant chunks at query time. Karpathy's LLM wiki takes a fundamentally different approach. Instead of searching for relevant fragments on the fly, the LLM reads raw source documents upfront and 'compiles' them into structured, interlinked Markdown articles. The wiki becomes a persistent, compounding artifact rather than a transient retrieval result.
The argument is partly about scale. At approximately 100 articles and 400,000 words, a personal research wiki fits comfortably within modern LLM context windows. Vector databases introduce retrieval noise and infrastructure overhead that, Karpathy argues, exceed their value at this scale. The compilation approach also produces something RAG cannot: a navigable, human-readable knowledge base with cross-references, backlinks, and synthesis across sources. A single ingested document may touch 10-15 wiki pages during compilation, creating connections that chunk-based retrieval would miss entirely. This challenges the industry's heavy investment in vector database infrastructure for personal knowledge management, though it remains an open question whether the approach scales to enterprise-sized corpora.