Most Agent Failures Are Context Failures, Not Model Failures
The most consequential insight reshaping how the industry builds AI agents is deceptively simple: when agents fail, the problem is almost always what information they were given, not the model's reasoning capability. This finding, echoed across multiple independent sources, inverts the dominant narrative that better models automatically produce better agents. Instead, the bottleneck is the information architecture surrounding the model -- what Andrej Karpathy calls "the delicate art and science of filling the context window with just the right information for the next step."
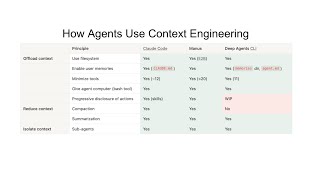
This reframing has practical implications that cascade through every layer of agent development. If context is the binding constraint, then the highest-leverage engineering work is not fine-tuning models or waiting for the next capability jump, but designing systems that select, compress, and sequence information correctly. Phil Schmid's breakdown identifies seven distinct components of context engineering -- system prompt, user prompt, short-term memory, long-term memory, RAG, tools, and structured output -- each representing a surface area where context can go wrong. The LangChain survey corroborates this: among organizations that have agents in production, 32% cite quality (not capability) as the top barrier, and a striking 67% failure rate afflicts agents without persistent memory. The message is clear: the model is rarely the weakest link.