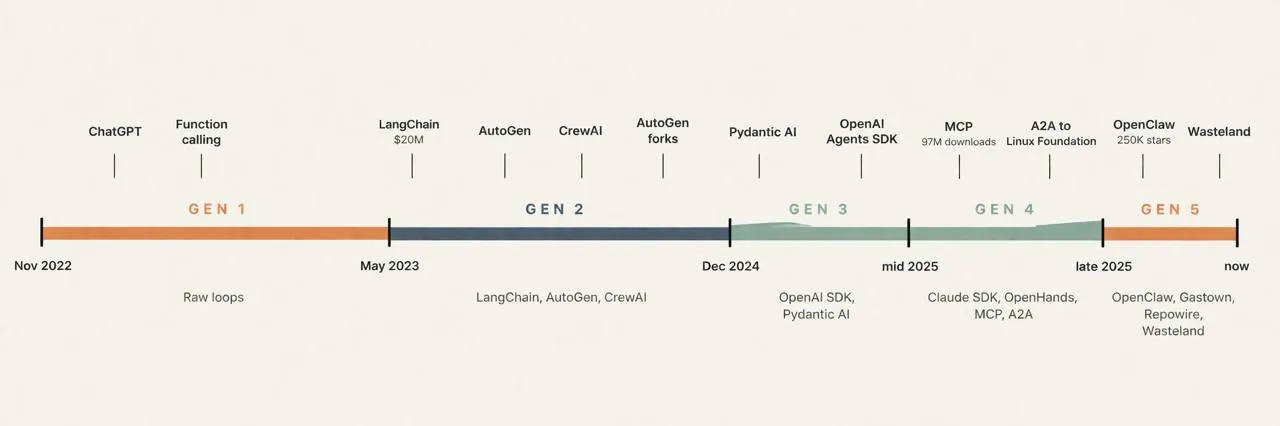
The 17x Error Problem: Why More Agents Can Make Things Worse
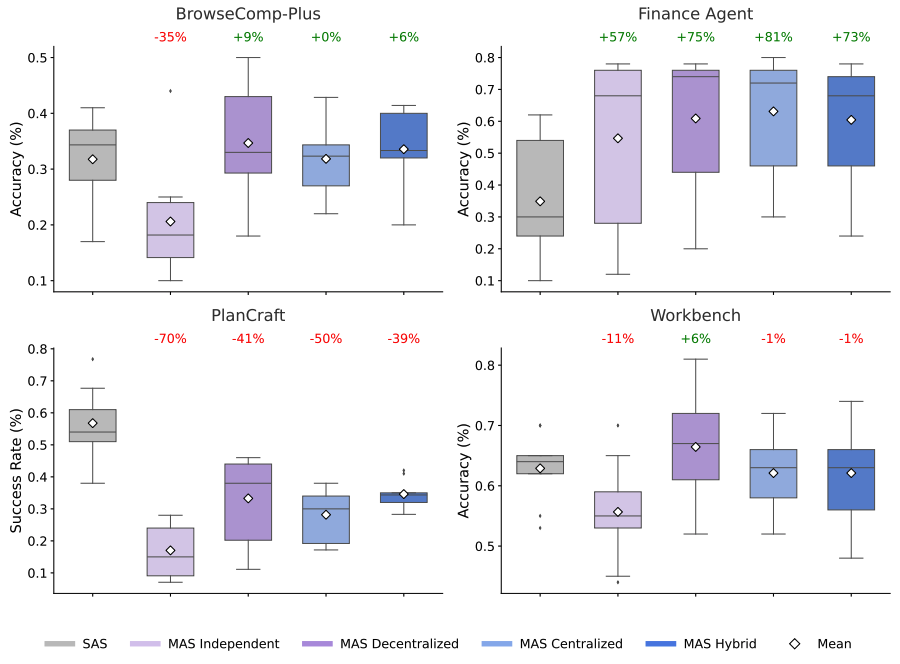
The prevailing narrative in AI agent development has been additive: more agents, more specialization, better results. Google Research's landmark study of 180 agent configurations across 5 architectures demolishes this assumption with hard numbers. Independent multi-agent systems amplify errors by 17.2x compared to single-agent baselines. Even centralized multi-agent architectures, which perform better, still amplify errors by 4.4x. The core issue is that when agents operate independently, each agent's errors propagate and compound through the system without correction.
The study's most actionable finding is that architecture selection depends critically on task structure. Multi-agent coordination improves performance on parallelizable tasks by 80.9%, a dramatic gain. But it degrades performance on sequential tasks by 39-70%, a catastrophic penalty. This means the same multi-agent framework that excels at research synthesis (inherently parallel) could fail badly at step-by-step code debugging (inherently sequential). Google's team built a predictive model that correctly identifies the optimal architecture for 87% of unseen tasks, suggesting the future isn't "single vs. multi-agent" but rather intelligent architecture selection. As the researchers concluded, smarter models don't replace the need for multi-agent systems -- they accelerate it, but only when the architecture is right.