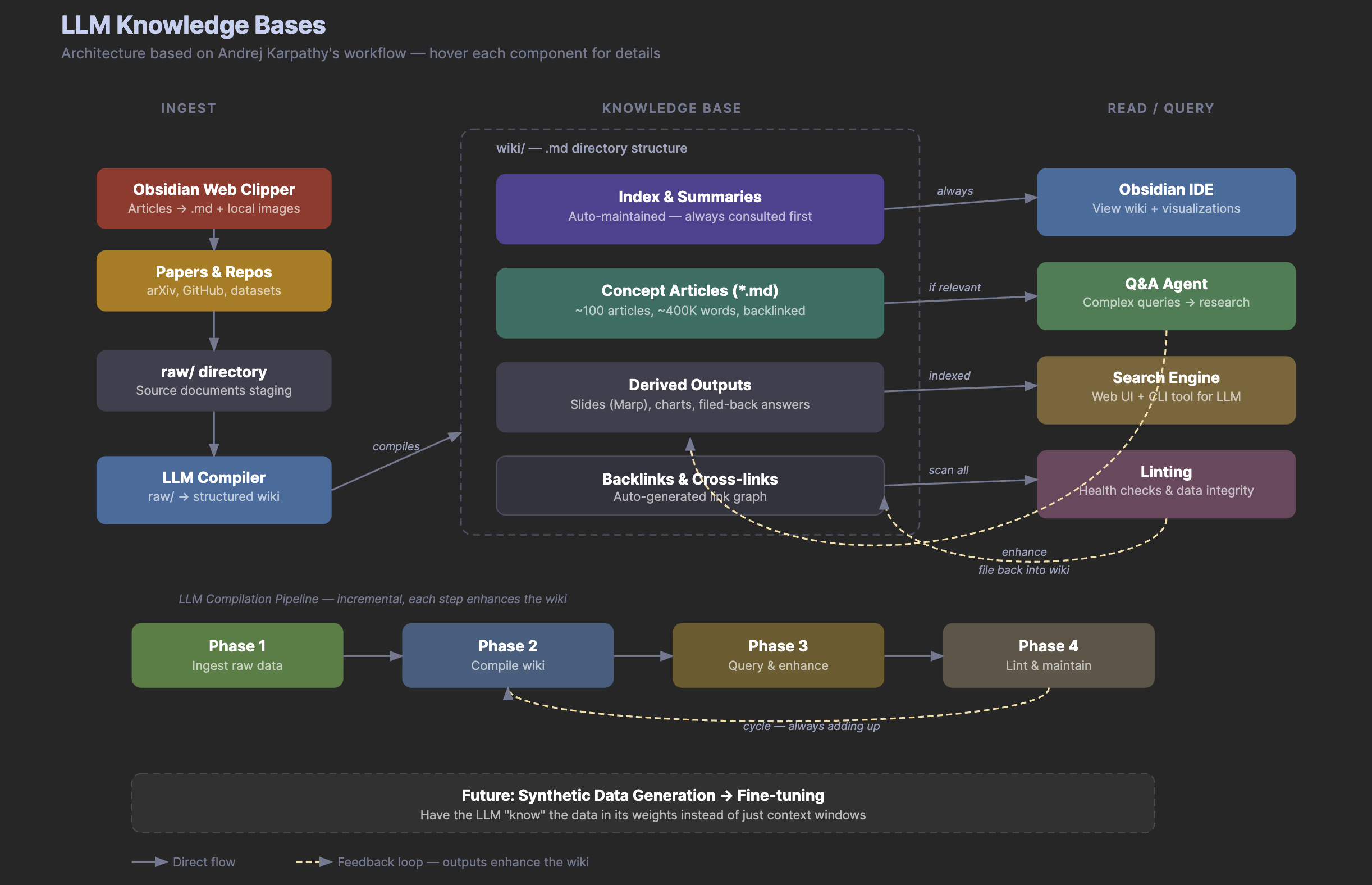
Why 'Compile Once, Update Incrementally' Threatens the RAG Industry
The most consequential claim embedded in Karpathy's LLM Wiki is deceptively simple: at personal and team scale, structured markdown files with an index are superior to vector databases and embedding pipelines. Traditional RAG treats every query as a cold start — retrieving document chunks, re-ranking them, and synthesizing an answer from scratch each time. LLM Wiki inverts this by having the LLM do the heavy synthesis work upfront during ingestion, producing cross-referenced markdown pages that accumulate knowledge over time. The index.md file replaces the vector index; the file system replaces the database.
This matters because the RAG ecosystem — vector databases like Pinecone, Weaviate, and Chroma, plus the surrounding tooling — has attracted billions in venture capital on the premise that retrieval-augmented generation is the canonical way to give LLMs access to private knowledge. Karpathy's argument is that for moderate-scale knowledge bases (his example: ~100 articles, ~400,000 words), expanding LLM context windows have made the embedding-retrieval-synthesis pipeline unnecessary overhead. The debate, as one analyst put it, centers on whether the industry has 'over-indexed on vector databases for problems that are fundamentally about structure, not similarity.' This is not a claim that RAG is useless at enterprise scale, but it is a sharp challenge to the assumption that RAG is the default starting point.