How Hybrid Attention Drained the Cost Out of a Million Tokens
The technical heart of V4 is a new hybrid attention design that pairs Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA). In conventional transformer attention, each new token attends to the full prior context, which is why long-context inference has historically been quadratic in pain — both in compute (FLOPs) and in the KV cache (the memory of prior tokens that the GPU must hold). DeepSeek's claim is that at a 1M-token context, V4-Pro needs only 27% of the per-token FLOPs and just 10% of the KV cache that V3.2 required. That is not a tuning win; it is a structural rewrite of where attention spends its budget.
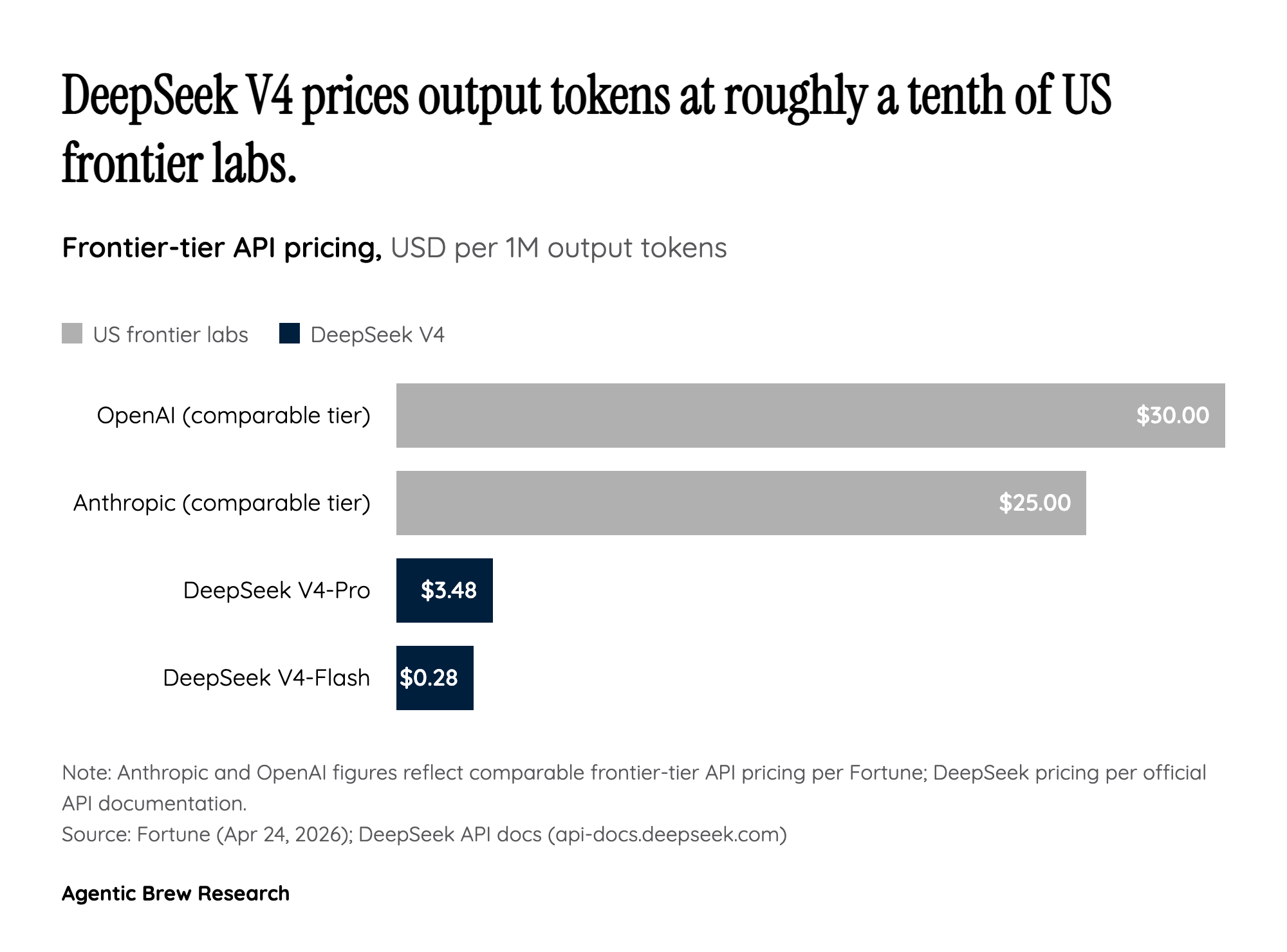
The knock-on effect is that 'long context' stops being a premium tier. DeepSeek made 1M tokens the default across all of its official services on launch day, rather than a paid add-on you have to opt into. For builders, this changes the unit economics of agentic workloads — codebase-wide refactors, multi-document legal review, long conversation memory — that previously made sense only as research demos. The architecture, in other words, is what makes the headline price possible. CSA + HCA is the mechanism; the $0.28-per-million-output-tokens sticker on V4-Flash is the receipt.