The bottleneck moved from model to context
For three years the dominant assumption was that better foundation models would unlock production agents. That assumption has quietly collapsed. The new consensus, articulated most directly by Harrison Chase, is that capability is no longer the limiter — context is. LangChain's central claim is that most of the time when an agent is not performing reliably the underlying cause is that the appropriate context, instructions and tools have not been communicated to the model [2]. Anthropic's Applied AI team frames the same shift differently: context must be treated as a finite resource with diminishing marginal returns, and the engineering job is to surface the smallest possible set of high-signal tokens rather than to flood the window [1].
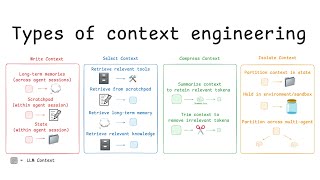
This reframing has practical teeth. Prompt engineering — the message-level instruction craft that dominated 2022-2024 and briefly carried six-figure salaries — is now treated as a subset of a broader discipline [10]. Context engineering covers everything that ends up in the model's view across a multi-turn agent run: system prompts, tool definitions, retrieved documents, memory, prior tool results, and the running message history. As Chase puts it on the Sequoia podcast, agent context is non-deterministic — you don't actually know what the context at step 14 will be because there's 13 steps before that that could pull arbitrary things in [3]. That non-determinism is why traces, not source code, are becoming the unit of debugging.