Why This Matters
The collision between AI's insatiable demand for training data and individuals' expectation of privacy is reshaping the social contract between technology companies and the public. Unlike previous waves of data collection -- targeted advertising, social media analytics -- AI training creates a qualitatively different problem: once personal information is encoded into model weights, it cannot be selectively deleted. This permanence transforms every piece of scraped data into an irrevocable transfer of informational value from individuals to corporations.
The economic incentives driving this conflict are enormous and asymmetric. Companies like Meta, Google, and OpenAI compete in a market where model capability is directly correlated with training data volume and diversity. The approximately 4,000 data brokers generating billion annually have created a shadow infrastructure that feeds AI pipelines with personal information most people never consented to share. Meanwhile, the privacy-preserving AI market is projected to reach nearly billion by 2035, signaling that the market itself recognizes this tension will only intensify. The fundamental driver is that data has become the primary input cost of AI development, and the cheapest data is the data taken without asking.
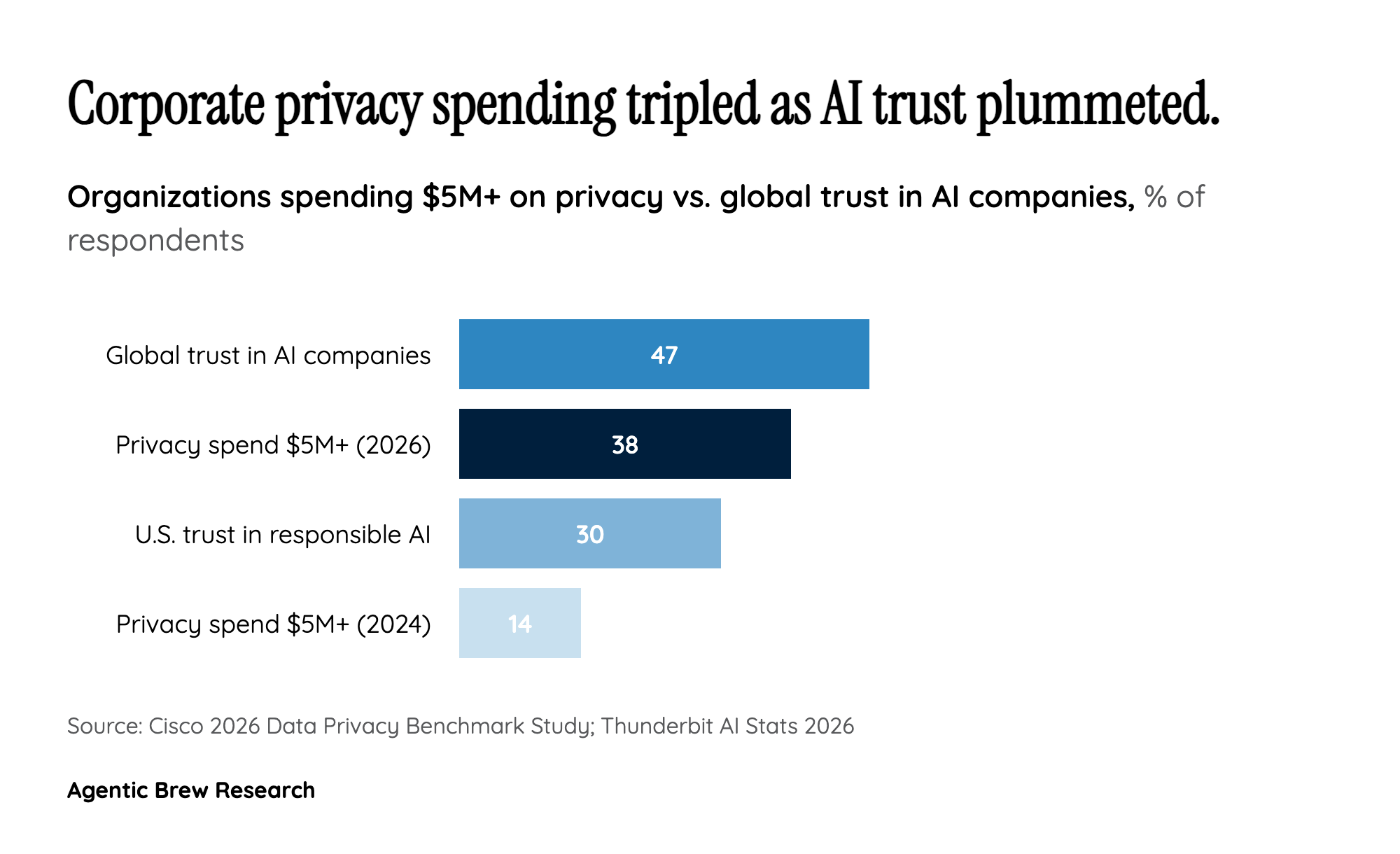
Public trust has eroded to critical levels. Only 47% of people globally trust AI companies, dropping to just 30% among Americans. When 81% of consumers fear misuse of AI-collected data, the legitimacy of the entire AI enterprise is at stake. Political figures like Senator Bernie Sanders are now engaging directly with AI companies about data collection practices, indicating this issue is crossing from technical policy into mainstream political discourse. The 33,000 engagements on Sanders' tweet about Anthropic's data practices suggest a public that is not just concerned but actively seeking accountability.