
Why Canva built its own design-native foundation model instead of renting frontier APIs
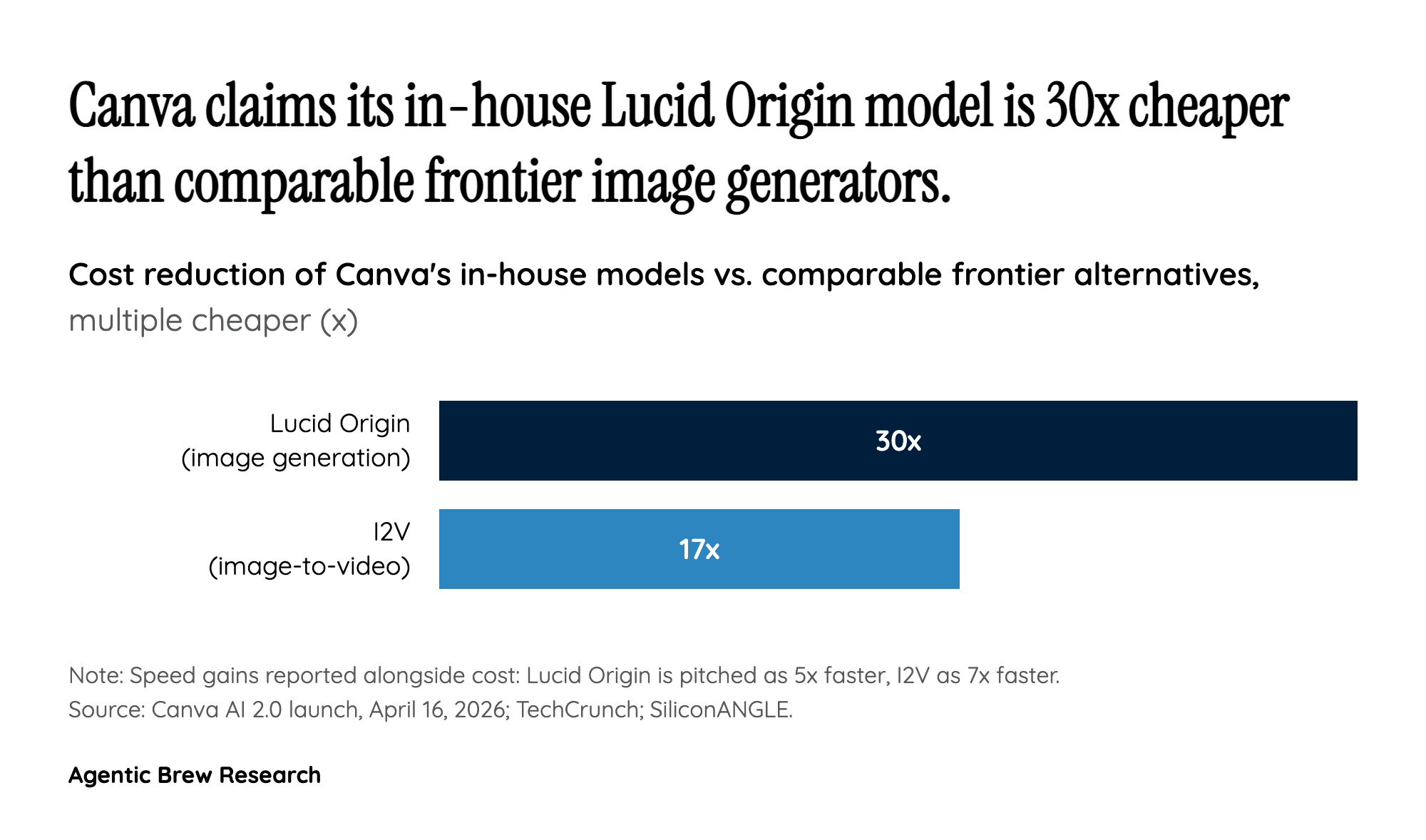
The headline economic claim of AI 2.0 is not a feature but a model: Lucid Origin, Canva's image-generation model, is pitched as 5x faster and 30x cheaper than comparable frontier alternatives, and its image-to-video (I2V) model as 7x faster and 17x cheaper. Those numbers explain a strategic choice. Canva has over 100 researchers inside its CORE (Canva Original Research and Exploration) group, and since acquiring Leonardo.Ai in 2024 it has been quietly building a design-layer foundation model rather than wiring Stable Diffusion or a frontier API underneath its canvas. At the volume Canva generates - 27 billion Canva AI uses to date, tripling in the past year - a 30x cost gap is not a margin story, it is the difference between offering AI for free under existing plans and gating it behind per-seat pricing.
That also reframes Object-Based Intelligence. Flat diffusion outputs are commercially cheap but editorially expensive, because every iteration is a full regeneration. A model trained to emit layered, editable objects lets Canva keep a user inside one design session across dozens of tweaks without a corresponding inference bill. Combined with Magic Layers - the Canva Design Model feature used more than nine million times in the month before launch - the pattern is clear: Canva is betting that vertically specialized, cheaper-to-serve models beat rented frontier horsepower for the narrow task of editable design generation, and it is using that cost structure as the price wedge that keeps AI free at scale.


