
Inference Is the Door AMD Walked Through
The most important sentence in AMD's release is not the headline beat — it is Lisa Su's line that "inferencing and agentic AI drive increasing demand for high-performance CPUs and accelerators." Inference is the workload of running already-trained models in production: the chatbot reply, the code completion, the agent calling a tool. It is fundamentally different from training, which compresses months of data into weights and rewards extreme interconnect bandwidth between thousands of GPUs. Inference rewards something else — fitting the model and its key-value cache in memory on as few chips as possible, then serving tokens cheaply. That is exactly the axis on which AMD's Instinct line was built: the MI300X shipped with 192GB of HBM3, the MI350 series moved to 288GB of HBM3e, and the upcoming Helios rack pairs 72 MI450 GPUs into a 31TB HBM4 pool delivering 1.4 exaFLOPS of FP8 compute. More memory per chip means a 70B- or 400B-parameter model can be served on fewer accelerators, which collapses both the bill of materials and the networking overhead.
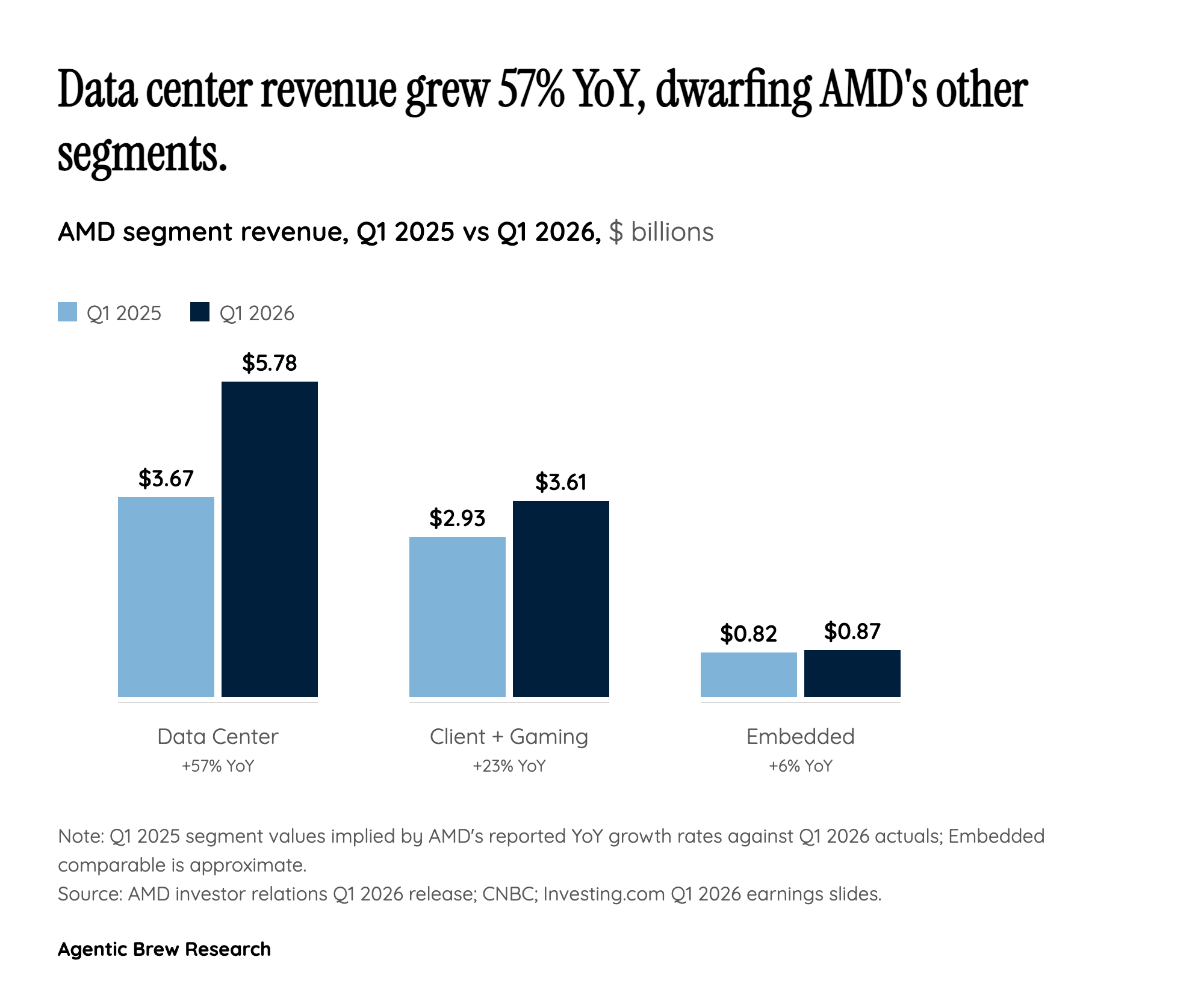
That explains why hyperscalers are willing to dual-source. In the training era they bought Nvidia because nothing else got the job done; in the inference era, where total cost of ownership is the dominant variable and frontier-model operators are now serving billions of queries a day, a chip with more memory and a more favorable price can win footprint even if it lags on raw FLOPS. The 57% data center growth this quarter is the financial expression of that shift — and it is why Lisa Su is comfortable forecasting "tens of billions of dollars in data center AI revenue next year" rather than a one-quarter pop. The question is no longer whether AMD has a credible AI silicon offering. It is how big a slice of the inference market it can lock in before Nvidia's Rubin generation arrives in volume.


