The Token Bill, Not the Benchmark, Is the Real Headline
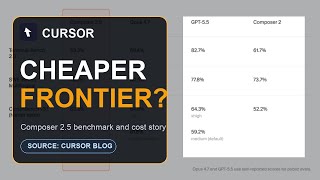
Composer 2.5's pricing is the part of the launch that actually reorders the market. At $0.50 per million input tokens and $2.50 per million output tokens [1], it sits roughly an order of magnitude below Claude Opus 4.7 on input and closer to 30x below it on output, while keeping CursorBench v3.1 and SWE-Bench Multilingual scores essentially level with the incumbent [2]. The Decoder summarised the practical consequence bluntly: Composer 2.5 matches Opus 4.7 and GPT-5.5 on CursorBench 3.1 but costs less than a dollar per task [3]. That single sentence is what Anthropic and OpenAI now have to answer.
The reason this matters more than a normal price cut is the shape of agentic workloads. A long-horizon coding agent doesn't make one expensive call; it makes thousands of cheap ones across hours of background work, reading files, re-prompting itself, and rerunning tests. Cursor community cost threads already show power users on $60 Cursor plans outlasting $100 Claude Code plans by routing implementation through Composer 2.5 while keeping a frontier model on call for hard reasoning. When per-token cost dominates the integral of all-day sessions, even a model that loses on peak intelligence wins on total bill — which is exactly the wedge Cursor is driving.