The 2.6B Model That Matches Eight-GPU Industrial Baselines
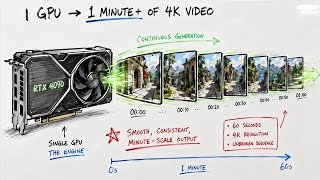
The headline number from the SANA-WM paper [1]is not the resolution and not the minute-long output — it is the parameter count. A 2.6B model trained on roughly 213K public video clips with 64 H100s over 15 days reports comparable visual quality to closed industrial baselines like LingBot-World and HY-WorldPlay at 36x higher throughput [2]. Until this release, single-GPU minute-scale world modeling at 720p with precise 6-DoF camera control was essentially out of reach for open-source work. Community reaction emphasized the contrast with prior open-source baselines, which typically required eight-GPU inference or dropped resolution to 480p to be tractable.
The practical effect is a shift in who can participate. The distilled variant denoises a 60-second 720p clip in 34 seconds on a single RTX 5090 with NVFP4 quantization [1]. That price point — one consumer-grade card, half a minute of compute per clip — pulls a class of controllable video generation experiments into the budget of an individual robotics graduate student. The Coders Blog frames the same point as 'world modeling at the edge of real-time' [3], which is the right framing: this is not just a smaller model, it is a model whose inference cost finally clears the bar where researchers can iterate.