The Reasoning-While-Speaking Knob
The headline change in GPT-Realtime-2 is not a louder voice or a smoother prosody — it is a five-position dial labeled reasoning_effort, with stops at minimal, low, medium, high, and xhigh. Crank it up and the model burns more thinking tokens before opening its mouth; leave it at the default low and it answers fast and shallow, the way prior real-time models always did. The trade-off is concrete: time-to-first-audio runs about 1.12 seconds at minimal effort and stretches to 2.33 seconds at high. That is a developer-facing latency budget exposed as a parameter, not a black-box choice OpenAI made for you.
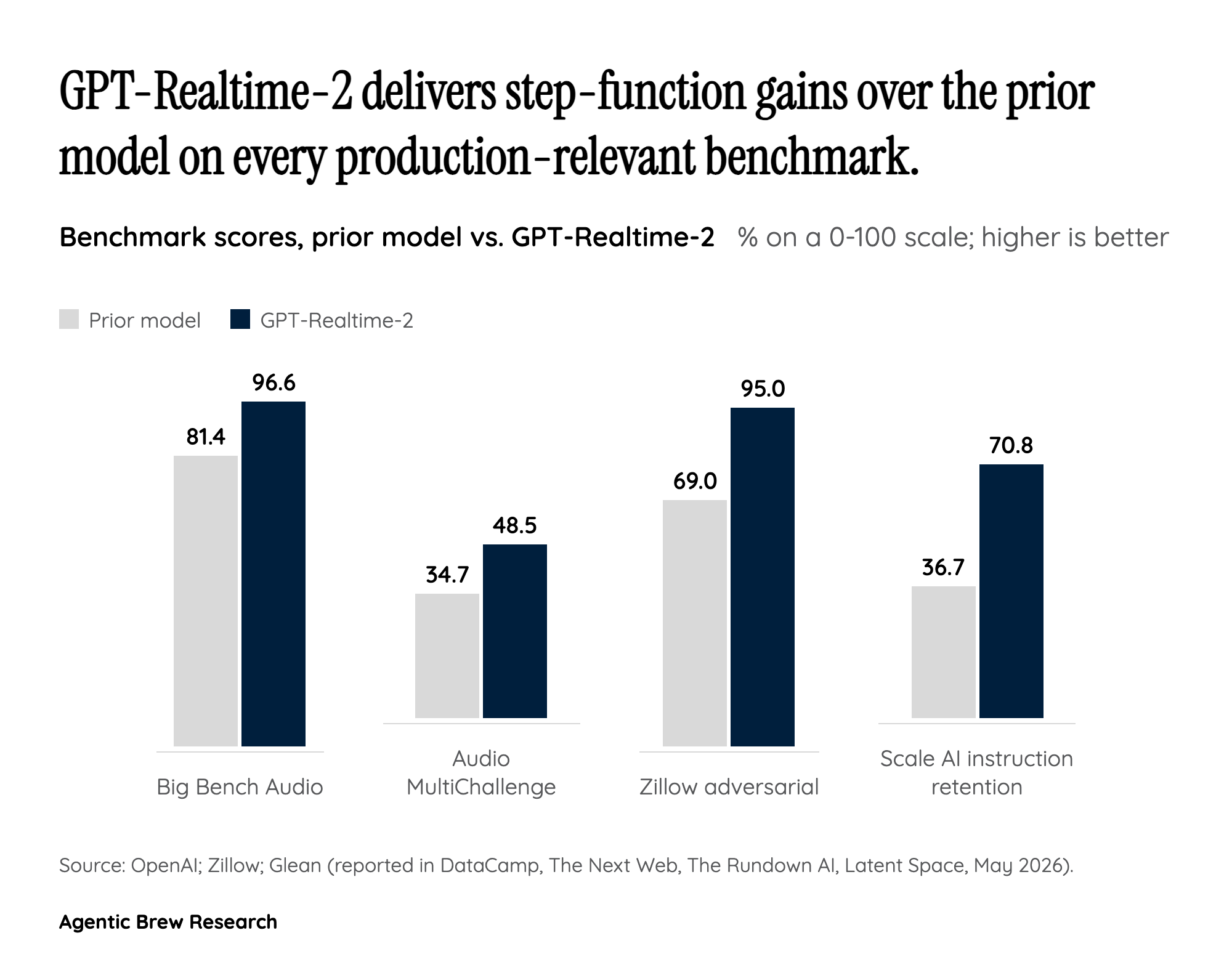
What the knob actually buys is captured in the benchmarks. On Big Bench Audio, GPT-Realtime-2 at high effort scores 96.6% versus 81.4% for the prior generation — a 15.2-point absolute jump. On Audio MultiChallenge instruction-following, xhigh hits 48.5% against 34.7% before, a 13.8-point gain. Beyond raw accuracy, the model can call multiple tools in parallel and narrate what it is doing while it does it, so a flight-search agent does not go silent for three seconds while a tool round-trips. When something does fail, the model can verbally signal trouble — 'I'm having trouble with that right now' — instead of producing the hallmark dead-air that has plagued every prior voice agent. Together those behaviors — graded reasoning, parallel tool calls, in-flight narration, graceful failure — are the mechanical reason early adopters describe this as a different category of voice agent rather than an incremental upgrade.