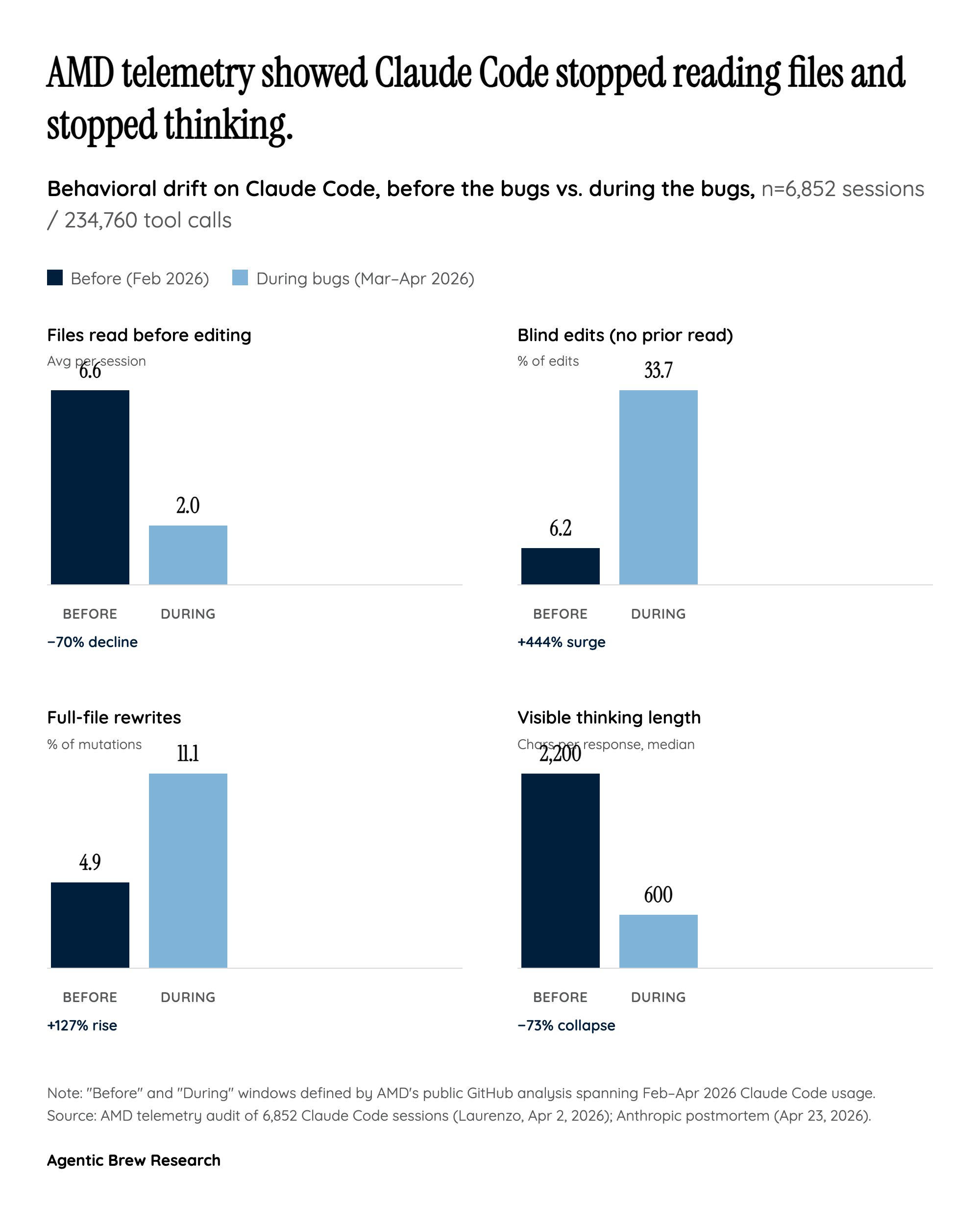
How Three Unrelated Patches Stacked Into One Quality Cliff
The postmortem's central, counterintuitive finding is that Claude Code's six-week slump was not one bug but three — each shipped by a different team, each plausible in isolation, and each interacting with the others in ways that defeated Anthropic's normal attribution tools. On March 4, a latency-focused change lowered the default reasoning effort from 'high' to 'medium'; Anthropic later admitted 'this was the wrong tradeoff.' On March 26, a prompt-caching feature meant to clear thinking from sessions idle more than an hour instead cleared thinking every turn — so Claude, in Anthropic's own words, 'would continue executing, but increasingly without memory of why it had chosen to do what it was doing.' On April 16, an innocuous-looking system instruction — 'Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.' — quietly taxed the model's working explanation space and dragged coding evals down ~3%.
Individually each change was defensible; together they produced compounding, overlapping symptoms — shallow reasoning, amnesia, clipped explanations — which is why Anthropic called this 'the most complex investigation we've had.' The lesson for every team shipping an agentic harness is that harness regressions do not behave like model regressions. They drift in, masquerade as model variance, and resist A/B rollback because the confounders overlap. Anthropic's eventual fixes were precise (revert April 7, v2.1.101 on April 10, v2.1.116 on April 20), but the six weeks between first symptom and last fix is the real story.