
What 52.5% Fewer Hallucinations Actually Buys You
OpenAI is leading the GPT-5.5 Instant launch with a single number: 52.5% fewer hallucinated claims than GPT-5.3 Instant on high-stakes prompts in medicine, law, and finance. A second number sits beside it — a 37.3% drop in inaccurate claims on user-flagged conversations — measured on real chats people had already complained about. The two metrics are doing different jobs. The 52.5% figure is the lab-bench claim, evaluated on curated high-stakes prompts where a confident wrong answer is most damaging. The 37.3% figure is the field claim, scored against the messy, in-the-wild conversations users have already singled out as broken. Together they let OpenAI tell two stories at once: the model is more accurate where it matters most, and the worst tail of past failures is meaningfully shorter.
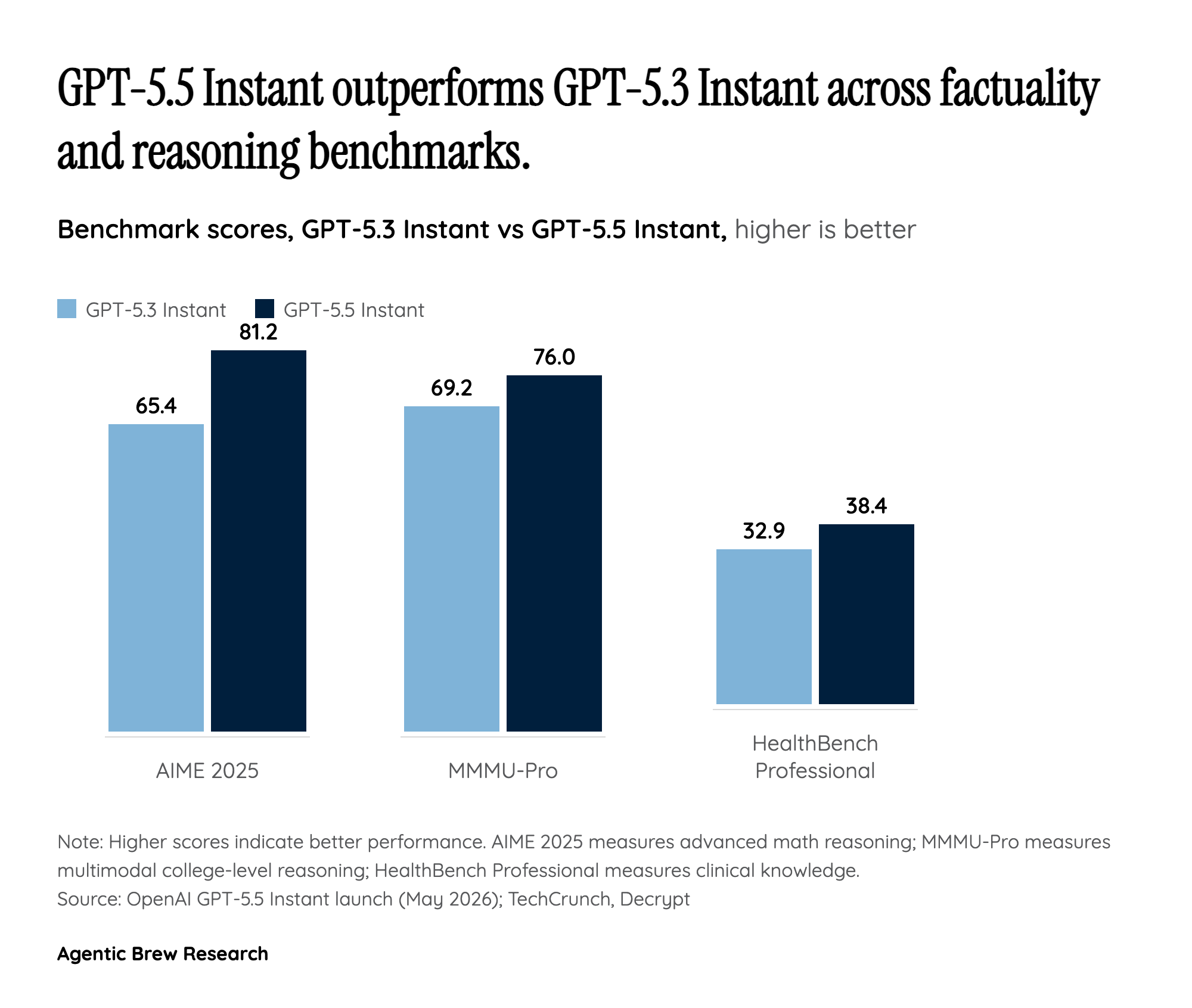
What this does not mean is that the model has stopped hallucinating. The framing in OpenAI's own communication is comparative — fewer than 5.3, not 'few in absolute terms' — and HealthBench Professional, a clinical-knowledge benchmark, only moves from 32.9 to 38.4. That is a real gain on a hard test, but it is also a reminder that even the upgraded default model gets roughly six in ten clinical professional questions wrong on this benchmark. The honest read of the launch is that OpenAI has narrowed the gap between an Instant-tier default and a thinking-tier model on factuality, not closed it. For builders shipping ChatGPT-backed features into regulated domains, the percentages are encouraging enough to revisit risk assumptions, but not enough to retire the human in the loop.


