The Pipeline Collapse
Until this release, almost every production voice agent stitched three components together: an automatic speech recognition (ASR) layer turned audio into text, a text LLM did the reasoning, and a text-to-speech (TTS) layer rendered audio back. Each handoff added latency, and reasoning could not see prosody, pauses, or hesitation because those were lost in transcription. GPT-Realtime-2 is, as The Next Web put it, 'a single model that handles audio in and audio out, with reasoning happening inside the audio loop rather than between transcription and synthesis steps.'
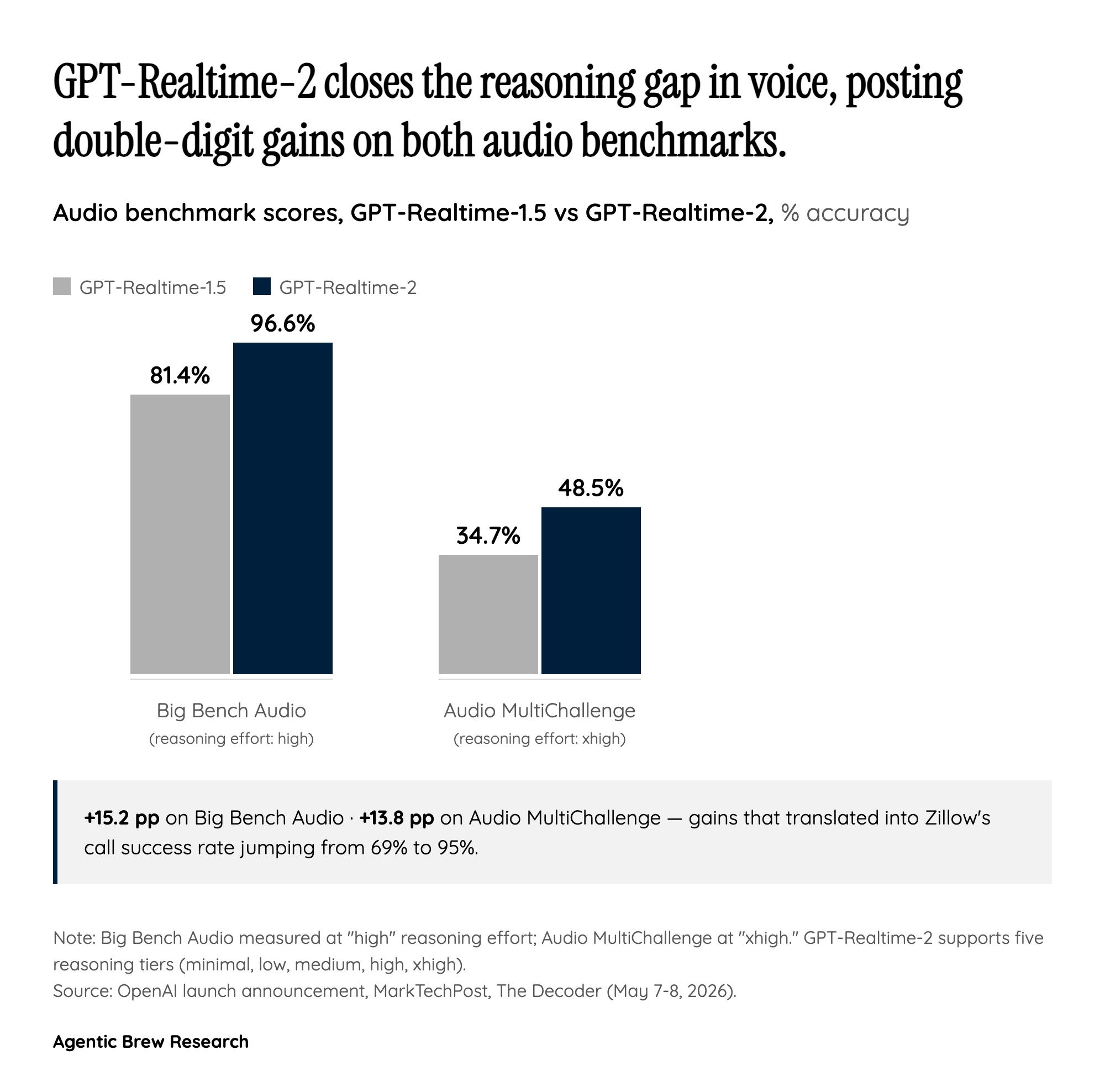
That architectural choice is what makes the new behaviors possible at all: simultaneous tool calls narrated mid-utterance via 'preambles' like 'one moment while I look into it,' interruption handling, and the ability to keep speaking while the model reasons. The 15.2-point jump on Big Bench Audio (81.4% to 96.6%) is a quantitative shadow of that architectural shift.


