
How V4 collapsed the price floor: a compute-efficiency story, not a margin story
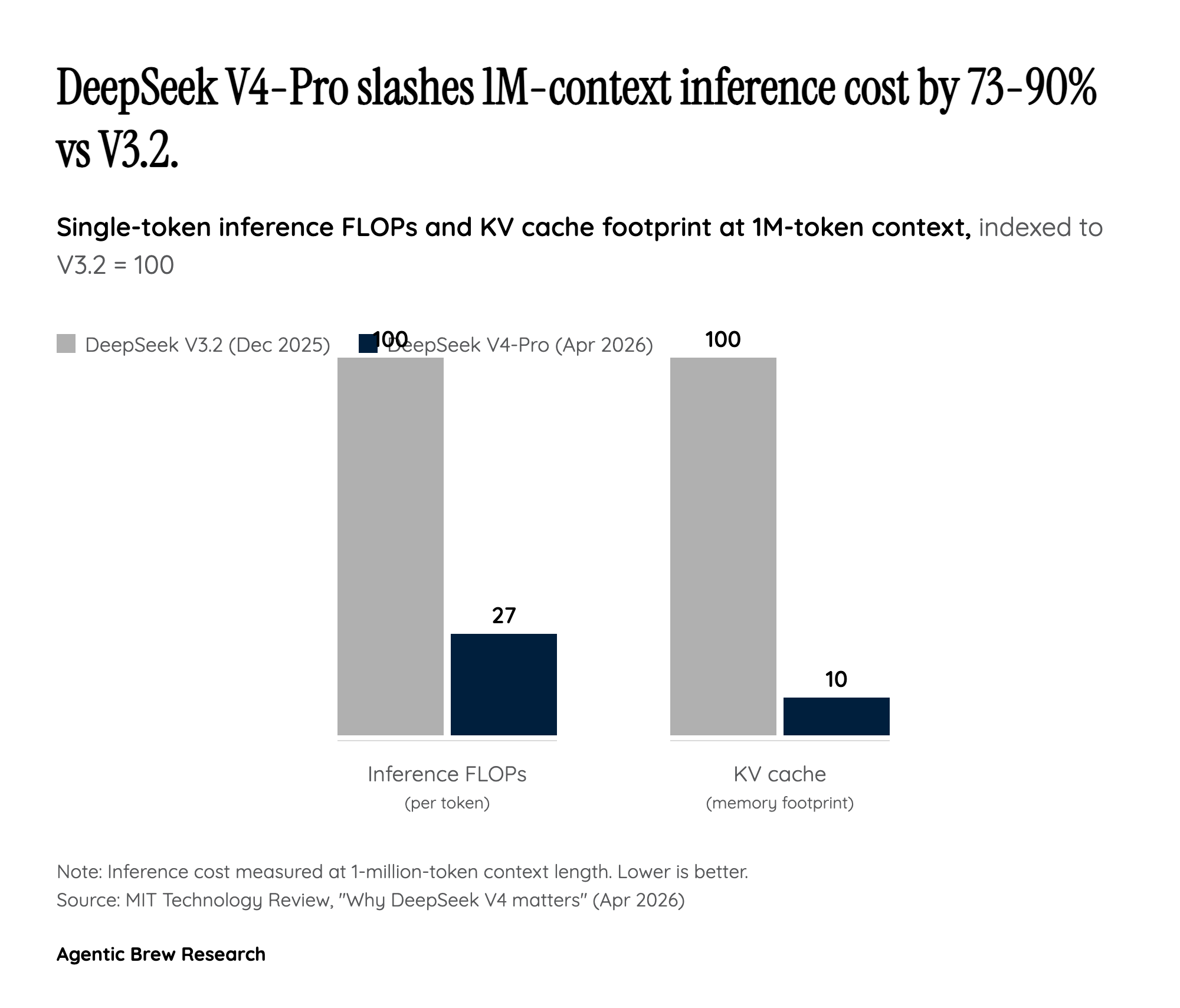
The headline number — V4-Pro at roughly one-sixth the per-token cost of Claude Opus 4.7 and one-seventh the cost of GPT-5.5 — is easy to read as a market-share land grab funded by patient Chinese capital. The architecture tells a more interesting story. DeepSeek paired a token-wise compression layer with its DeepSeek Sparse Attention (DSA) mechanism so that a 1.6 trillion parameter MoE only activates 49 billion parameters per token, and at the 1-million-token context setting V4-Pro consumes just 27% of the single-token inference FLOPs and 10% of the KV cache footprint that V3.2 needed for the same workload. That is the actual reason the price sheet looks the way it does. DeepSeek is not selling intelligence at a loss — it has rebuilt the cost basis underneath it.
For builders, this matters more than the benchmark scores. A 1M-token context is largely theatrical at GPT-5.5 prices because nobody can afford to fill it; at $1.74 per million input tokens the long-context regime becomes the default rather than the special case. DeepSeek has also signaled further price cuts as Huawei's Ascend 950 supernode supply ramps in the second half of 2026, which means the V4 sticker is a ceiling rather than a floor. Frontier closed-source labs now have to decide whether to defend price or defend gross margin — and the open-weights MIT license under V4 means even the choice to defend price will not stop self-hosters from undercutting them in private deployments.


