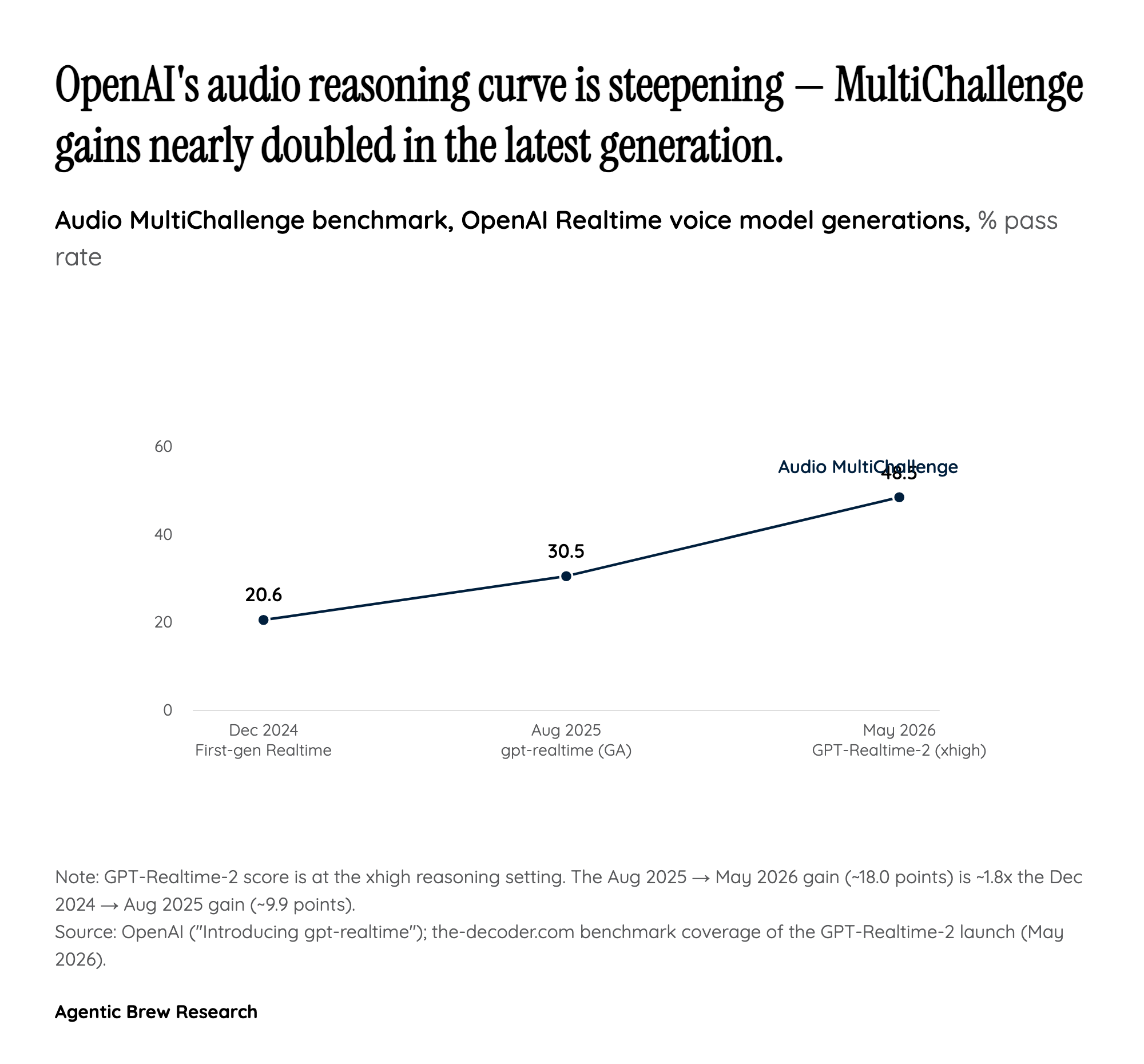
Reasoning grafted onto a streaming voice path — and the latency tax it introduces
The headline claim is that GPT-Realtime-2 is OpenAI's first voice model with GPT-5-class reasoning, exposed via five adjustable levels from minimal to xhigh. In practice, that means the model can deliberate mid-conversation: weigh tool calls in parallel, plan a multi-step action, and emit a verbal preamble like 'let me check that' to keep the human engaged while it thinks. Combined with a 128K-token context window — which OpenAI characterizes as roughly one to two hours of dense raw audio — the architecture is unambiguously aimed at long-running voice agents that must hold state across a real call rather than answer one-shot prompts.
The tension is that reasoning costs time, and voice users famously punish latency. Developer-community responses surfaced this directly: one early tester argued the new 'thinking' gains do not translate cleanly to a voice surface where users expect instant replies, and others felt the model came across as smarter but more robotic than the GPT-4o voice demos from May 2024. OpenAI's design answer is the reasoning-level dial plus the preamble pattern — let the model talk while it thinks — but builders will need to pick a level per turn rather than per session, and treat 'minimal' as the default for chitchat and 'xhigh' as a tool the agent reaches for only when a task actually requires deliberation.