Why This Matters
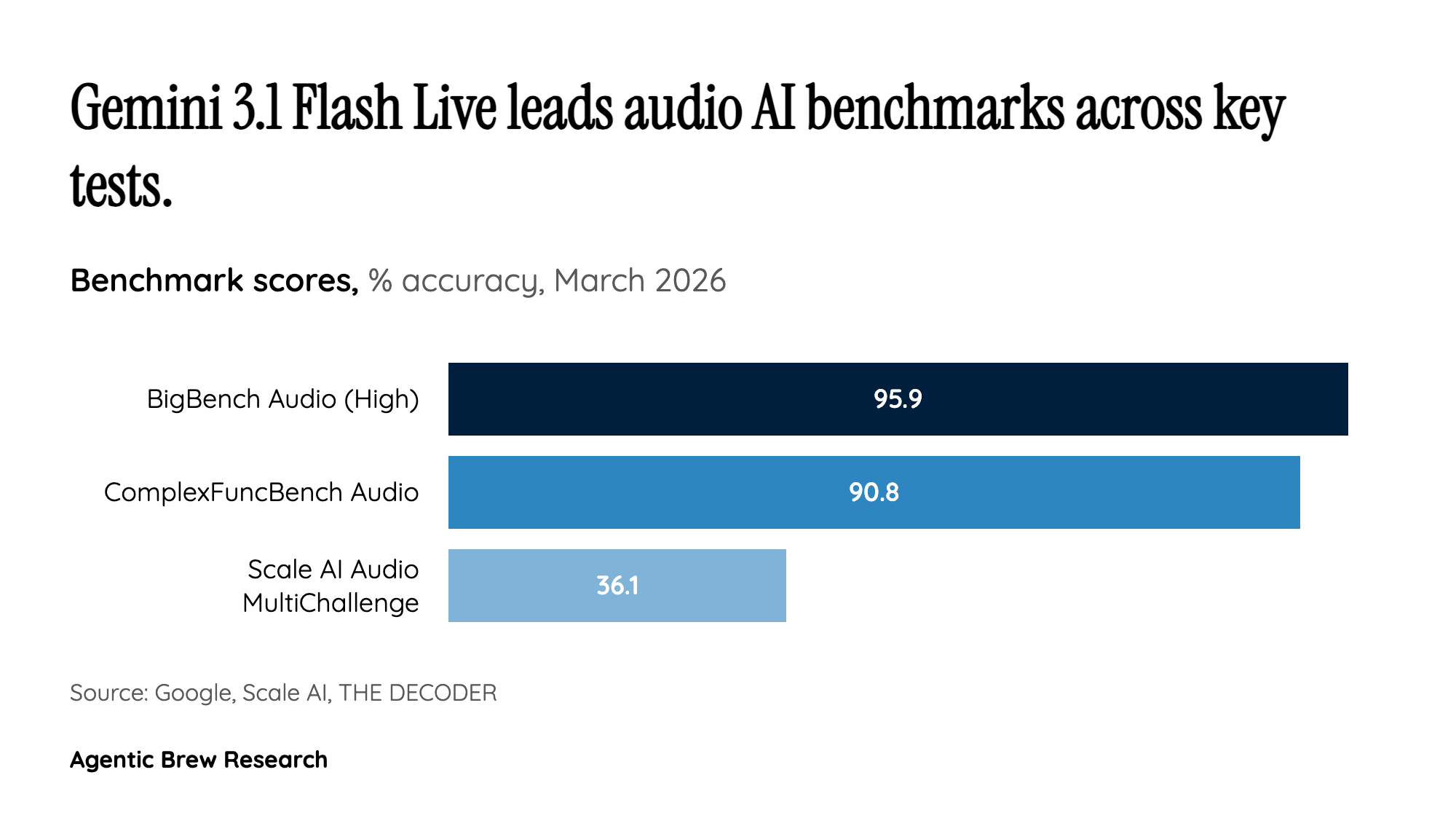
Gemini 3.1 Flash Live represents a significant inflection point in real-time voice AI. The model is not merely an incremental update -- it is a speech-to-speech system that bypasses the traditional text-in-the-middle pipeline, enabling more natural, emotionally nuanced, and low-latency voice conversations. It can recognize acoustic nuances like pitch, pace, and emotions, filter background noise more effectively, and follow conversation threads for twice as long as previous models. These improvements address the core friction points that have kept voice AI from feeling truly conversational.
The simultaneous global expansion of Search Live to over 200 countries transforms how billions of users can interact with Google Search. Rather than typing queries, users can now point their phone camera at objects and have back-and-forth voice conversations that draw on visual context from the camera feed. This is not a research demo -- it is a production deployment across Google's entire global search infrastructure, powered by the new model. The combination of a substantially improved voice model with worldwide distribution gives Google a formidable lead in the voice-first AI race.